この記事は、RevComm Advent Calender 20 日目の記事です。
はじめに
こんにちは。服部 (@keigohtr) です。趣味は MLOps 調査とクラフトビールです。最近はエルゴノミクスキーボードを探し続けています。担当は RevComm Research 配下の開発部のエンジニアリングマネジメントです。本日は「RevComm Research 開発部ってどんな場所なの?」に答えたいと思います。
会社紹介
RevComm は電話営業や顧客応対を可視化する音声解析AI搭載型のクラウドIP電話「MiiTel(ミーテル)」を開発しています。
私の所属する RevComm Research は MiiTel のコアバリューである音声認識や話者分離、感情認識などの機能を開発しています。プロダクトは順調に成長し続けていまして、ユーザー数の増加に比例して解析対象の商談数も増え続けています。お客様が安心してサービスを使えるように、Research の開発部には機械学習サービスの高い安定性と高いスケーラビリティが求められています。
ML推論環境の変遷
RevComm Research では構成の大刷新を進めています。私が入社した当初(ちょうど 1 年前の 2021 年 12 月)の構成はざっくりと下図のようになっていました。EC2 を使ったシンプルな構成ですが、Worker に多くの処理(e.g. ロジック、機械学習処理)を押し込めていたことや、長年保守し続けてきた AMI に色々と限界を感じたことから、マイクロサービス化してコンテナベースの運用に切り替えようとしていた時期でした。
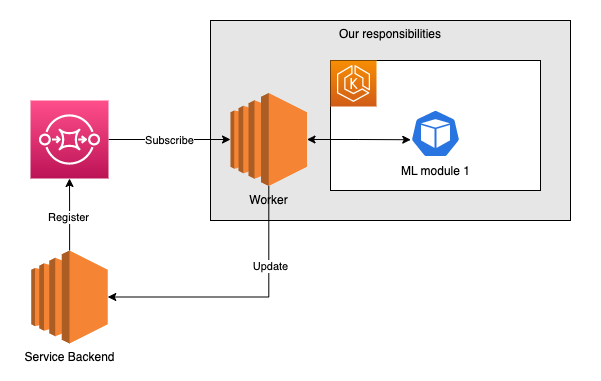
そして下図が現在の構成です。移行作業としては、まず Worker に押し込めていたいくつかの処理をマイクロサービスとして分離しました。Worker の規模がある程度小さくなったので、現在は Worker をコンテナ化しています。ただし構成としてはまだまだ道半ばといったところです。

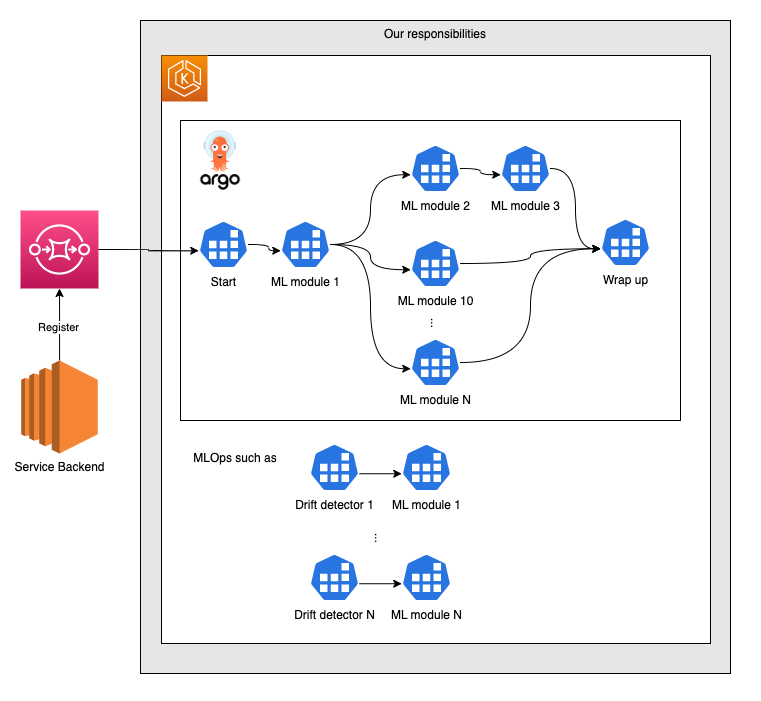
現時点で目指している構成は下図になります。Worker を完全に分解してワークフローエンジンに乗せて管理します。ワークフローエンジンの恩恵をフルに享受するのが狙いです。ML モジュールは用途に応じてサービスとバッチを使い分け、コストとリソースの最適化を図ります。この構成は理想に対するベースであり、ここから更に DevOps や MLOps のベストプラクティスを導入していく予定を立てています。やりたいことが多いのでワクワクしています。
DX の変遷
この 1 年間に整備した開発者の環境について紹介します。
モノレポの採用
RevComm Research には多くの ML モジュールがあります。私が入社した当初は Worker の中に全ての ML モジュールが内包されている状態でした。機械学習のライブラリも Tensorflow、PyTorch、sklearn と使っており、ライブラリの依存関係で身動きが取れない状態でした。そこで ML モジュールを Worker から分離してマイクロサービス化するというプロジェクトが進行しました。
Worker から分離したマイクロサービスはモノレポで管理しています。メリットは
- CICD のセットアップが一箇所で済む。
- 共有コンポーネント(e.g. Log Formatter, gRPC proto)の参照が簡単にできる。
- 共有コンポーネントを変更した時、依存する全てのコンポーネントのテストが簡単にできる。
- チームの技術的な知見を集約できる。
- トラブルシュートのときにここをみれば良いので、認知負荷を下げることができる。
ビルドシステムには pants build を採用しました。有名なビルドシステムには Bazel がありますが、RevComm Research は Python をメインに開発していたこともあり、Python との親和性の高さを評価して pants build に決めました。pants build によってモノレポの中の各プロジェクトやパッケージの依存関係が明らかになり、CI ではコードの変更箇所に関連するテストだけが実行されるようになりました。モノレポではコードの規模が大きくなるにつれてテスト時間やビルド時間が長くなるので、先行投資として最初期からビルドシステムを組み込みました。
その他の工夫としては、CODEOWNERS の設定があります。CODEOWNERS は GitHub の機能で、特定のディレクトリに対して責任者を設定できます。執筆現在の時点で我々がモノレポで管理しているものは、Python で書かれた複数の ML モジュールと、各 ML モジュールで共有するパッケージ、そして ML モジュールを配信するために必要な Terraform リソースです。それぞれに対して CODEOWNERS を設定し、コードレビューでは CODEOWNERS の承認を必須としました。こうすることでエンジニアの Ownership を育むとともに、CODEOWNERS に任命されたエンジニアがリソースの中で守りたい一貫性を守れるようにしました。 例えば、「DDD を採用しているのに気づいたらドメインが漏れ出していた」という事態は CODEOWNERS の設定で避けやすくなります。
GitOpsの採用
モノレポの採用の部分で CI を整備しました。次は CD です。私が入社した当初は EKS にはたったひとつの ML モジュールのみが配信されており、そのリリースは手作業で Kustomize を実行していました。そしてチームで Kubernetes を触れるエンジニアは一人だけという状況で、つまりリリースができるのも一人だけという状況でした。CD に ArgoCD の検討はされていたものの運用には至っておらず、CD の自動化は急務でした。
CD は ArgoCD を採用しました。ArgoCD はチームで運用には至っていなかったものの、既にメンバーが検討したときの資産がいくつかあったこともあり、再整備をして運用することにしました。コードはモノレポで管理し、マニュフェストは別のレポジトリを用意し、マニュフェストレポジトリを ArgoCD で監視しています。マニュフェストレポジトリにある各 ML モジュールのイメージタグの更新は GitHub Actions で自動化しています。開発環境とステージング環境は ArgoCD の Auto Sync を有効にして、コードの変更を即座に環境に反映するようにしています。本番環境はまだテストが十分に自動化できていないこともあり Auto Sync を有効にできていないですが、将来的には sync windows を設定して営業時間外に自動的に更新できるようにする予定です。
執筆現在の時点で、ArgoCD は Pull 型の GitOps で使っています。Pull 型の GitOps を採用した理由はセキュリティ面でのメリットです。リリースするときに GitHub 側に EKS クラスタへのアクセス権限を持たせなくて済みます。
おわりに
今回紹介したのは機械学習の推論環境です。今回紹介した内容以外にも推論環境でやるべきことはまだまだあります。例えば A/B テスト、Canary release、Feature flag、Traffic shadow、etc。また、機械学習の学習環境もやりたいことがたくさんあります。RevComm Research では Engineering / DevOps / MLOps を積極採用していますので、皆様の応募をお待ちしています。