※この記事はリサーチエンジニアのJennifer Santosoによる記事『IPSJ 266th Natural Language Processing & 158th Speech Language Information Processing Joint Research Presentation Meeting - Presentation and Participation Report』を翻訳したものです。
はじめに
RevComm Researchのサントソです。12月中旬に開催された研究会に参加し、日頃の研究成果を登壇してきました。今回は「Generative Error Correction for Product Names with Phonemic and Lexical Constraints」というテーマで、最新の成果を報告しました。多くの専門家と議論を交わし、非常に有意義な時間を過ごすことができました 。
学会の概要
https://www.ipsj.or.jp/kenkyukai/event/nl266slp158.html
本学会は、国内最大級のIT団体である情報処理学会(IPSJ)が主催しています。今回は、言葉をコンピュータで扱う「自然言語処理(NL)」と、音声の解析・生成を担う「音声言語処理(SLP)」の2つの研究会が合同で開催されました。これらは年数回、分野を横断した議論の場として共催されており、口頭発表を中心に最新の研究報告が行われます。
開催期間
2025年12月15日〜17日
開催地
京都テルサ(京都市)(https://www.kyoto-terrsa.or.jp/)
対象分野
主に自然言語処理(NL)および音声言語処理(SLP)を対象としています。特に、大規模言語モデル(LLM)を用いた音声認識の高度化や、ドメイン特化型の言語処理が大きなテーマとなっていました 。
発表件数
- 口頭発表: 28件
- 招待講演: 2件
- 国際学会参加報告: 2件(INTERSPEECH 2025とACL2025)
計32件の非常に濃密なセッションが組まれました。

参加人数
およそ200人(オンライン参加者が含む)
会場の様子


登壇報告
ビジネス会話における音声認識(ASR)の精度向上、特に「商品名」の誤認識をLLMでいかに修正するかという研究を発表しました 。研究会にある発表はほとんど日本語で行われましたが、今回の発表・質疑を英語で行いました。
題目
Generative Error Correction for Product Names with Phonemic and Lexical Constraints(音韻的・語彙的制約を用いた商品名の生成的な誤り訂正)
背景・モチベーション
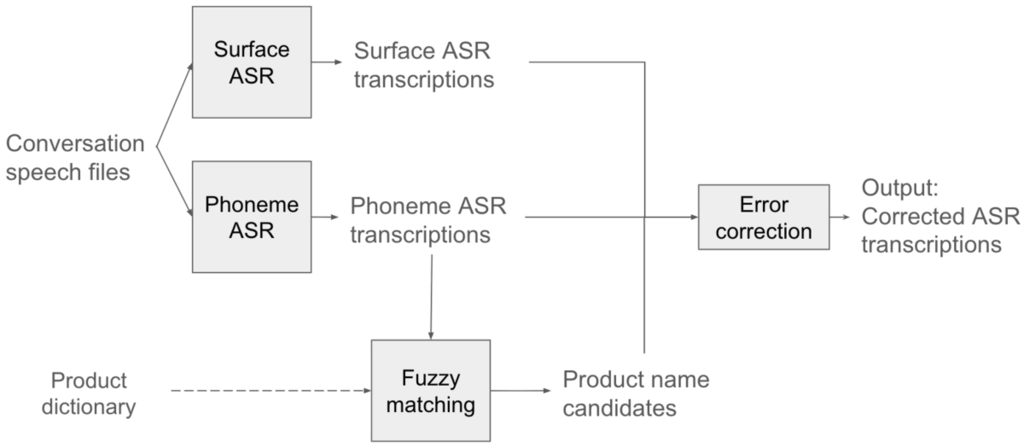
本研究では、ASRシステムがしばしば苦手とする製品名や型番といった用語を、LLMベースのフレームワークを用いて後処理・修正する手法を提案しました。具体的には、音声から抽出した音声情報を製品辞書を用いてLLMプロンプトに統合します。これにより、コアASRモデルを再学習することなく、語彙外(Out-of-vocabulary; OOV)用語を正確に修正することが可能になります。
英語と日本語の両方のデータセットを用いた実験結果では、製品名認識精度(Accuracy)が大幅に向上しました。この開発により、専門用語が頻繁に使用されるビジネス環境における自動議事録の品質が大幅に向上すると期待されます。
本研究の主な貢献
本研究の主なポイントは以下の2点です:
- データセット構築プロトコルの提供: 商品名や型番に特化した、会話音声データの構築手法を提案しました 。

- 新たな誤り訂正フレームワークの提案: ASRを再学習することなく、音素情報(Phoneme)と商品辞書(Lexical)、そして会話の文脈を融合させて、ゼロショットで誤りを訂正する手法(Generative Error Correction; GEC)を開発しました 。
実験の結果、英語・日本語の両データセットにおいて、商品名の認識精度が大幅に向上することを確認しました 。
いただいた質問
発表後には、20分間の発表に対して5分間の活発な質疑応答が行われました。
Q1. ファジーマッチングの具体的な閾値とその理由は?
回答: 0.6から0.9の範囲を0.05刻みで検証し、最適な値を決定しました 。これは、検索の成功率と、LLMに渡す情報のノイズを抑える精度のバランスを最適化するためです 。
Q2. データセットの話者数が少ないようだが、テスト設定として一般的か?
回答: 本研究では、英語・日本語それぞれ男女2名ずつのリファレンスボイスを使用して合成データを作成しました 。この分野では話者数よりも商品名の多様性が重視されます。認識結果のばらつきが十分に見られるよう設定しているため、評価設定として一般的だと考えています。
Q3. 会話シーケンスの代わりに、要約を文脈として利用できるか?
回答: 本研究の目的は、商品名の認識精度を高めることでビジネスにおけるインサイトを明確にすることにあります。正確な要約を作成するためには、その前提となる商品名の正しさが不可欠です。もし誤認識が含まれたまま要約を行ってしまうと、重要なキーワードが抜け落ちたり、内容の質が低下したりする恐れがあります。その結果、LLMが本来注目すべき商品名を認識できず、修正能力が十分に発揮されない可能性があるため、要約ではなく生の会話シーケンスを直接文脈として活用する手法が適していると考えています 。
気になる発表
招待講演1:言語モデルのマルチモーダル言語理解能力
LLMが言語や視覚情報をどの程度「理解」しているのかを4つの側面から検証した刺激的な講演でした。逐次通訳への応用では、プロンプト制御によりデータ不足を克服し、従来手法を上回る精度を実現しています。一方、視覚情報を用いた調音推測などの実験を通じ、絶対的な視覚理解には依然として課題があるという知見が示されました。
招待講演 2: 音声コーパスの過去・現在・未来
本講演では、AI時代における音声データに関する提言が提示されました。日本語およびアジア言語のコーパス拡充に向けた国際協力の重要性、そしてLLM開発のためのデータの「量」と厳密な実験のためのデータの「質」のバランスを取る必要性が強調されました。また、会話音声、特に顔データを含む会話音声は、厳格な倫理的管理と同意取得を必要とするセンシティブな個人情報であることも強調されました。
国際学会参加報告
- INTERSPEECH 2025: ASRとLLM、そして自己教師学習(Self-supervised learning; SSL)の融合が主流のトレンドであると報告されました。音声言語モデル(Speech Language Models)の台頭により、この分野はパラ言語理解、全二重対話、ゼロショットTTSへと拡大しています。
- ACL 2025: ARR(ACLローリングレビュー)システムに関する知見が共有されました。議論は、改善のための再提出の重要性と、堅牢な反論の必要性に焦点が当てられました。また、混雑した会場で注目を集めるための、視覚的にミニマルでありながらインパクトのあるポスターを作成するためのヒントも提供されました。
まとめ
12月の研究会にて、私たちの最新の研究成果を共有できたことを光栄に思います。約200人の参加者が集まった会場は熱気に包まれ、招待講演や国際学会の報告を含め、LLMを用いた音声処理の可能性について活発な議論が交わされていました。
専門家の方々と直接対話することで、非常に有意義なフィードバックをいただくことができました。チーム内で議論を尽くして準備した発表でしたが、こうした対面での議論を通じて、新たな課題や今後の研究の方向性がより明確になったと感じています。
RevComm Researchでは、今後も継続的な研究と発表を通じて、コミュニケーションを科学する挑戦を続けていきます。現在、私たちと共にこれらの刺激的な技術課題に取り組んでいただける仲間を募集しています。