RevComm Researchの加藤集平です。8月下旬に音声処理のトップカンファレンスであるINTERSPEECHで発表するため、また引き続いて行われたISCA Speech Synthesis Workshop (SSW) に参加するためにヨーロッパに出張をしてきました。今回の記事では、INTERSPEECH, SSWおよび私の発表について紹介いたします。
加藤集平(かとう しゅうへい)
シニアリサーチエンジニア。RevCommには2019年にジョインし、音声処理を中心とした研究開発を担当。ADHDと付き合いつつ業務に取り組む2児の父。
個人ウェブサイト X
→ 過去記事一覧
INTERSPEECH
会議の概要
International Speech Communication Association (ISCA) が主催する国際会議で、音声処理分野を専門に扱う国際会議としては最大級の規模です。2004年にそれまで行われていた2つの国際会議European Conference on Speech Communication and Technology (EUROSPEECH) とInternational Conference on Spoken Language Processing (ICSLP) を正式に統合した国際会議としてINTERSPEECHが開催され、以降毎年開催されています。
開催期間
2023年8月20日〜24日(チュートリアル1日+発表4日)
開催地
The Convention Centre Dublin、ダブリン(アイルランド)
対象分野
音声処理・音声コミュニケーション全般(音声認識・音声合成・音声変換・音声翻訳・音声符号化・音声対話システム・音声知覚・音声生成など)
発表件数
1,097件(採択率49.7%)
参加人数
およそ2,000人
会場の様子
4日間で1,000件を超える発表を行うため、7つのオーラルセッション(口頭発表)と4つのポスターセッションが並行しての進行でした。
会場の大きさは様々でしたが、どの会場も多くの参加者で賑わっていました。


私の発表について
題目(リンク先は論文のアーカイブです)
Speech-to-Face Conversion Using Denoising Diffusion Probabilistic Models (ノイズ除去拡散確率モデルを用いた音声から顔への変換)
本研究の主な貢献
Speech-to-face(音声を入力として、それに適した顔画像を出力するタスク)において、初めて拡散モデル(ノイズ除去拡散確率モデル)を導入しました。その結果、よりシンプルかつ柔軟なシステムで、これまでの研究よりも高解像度 (512×512) の顔画像を生成することに成功しました。
ポスター資料
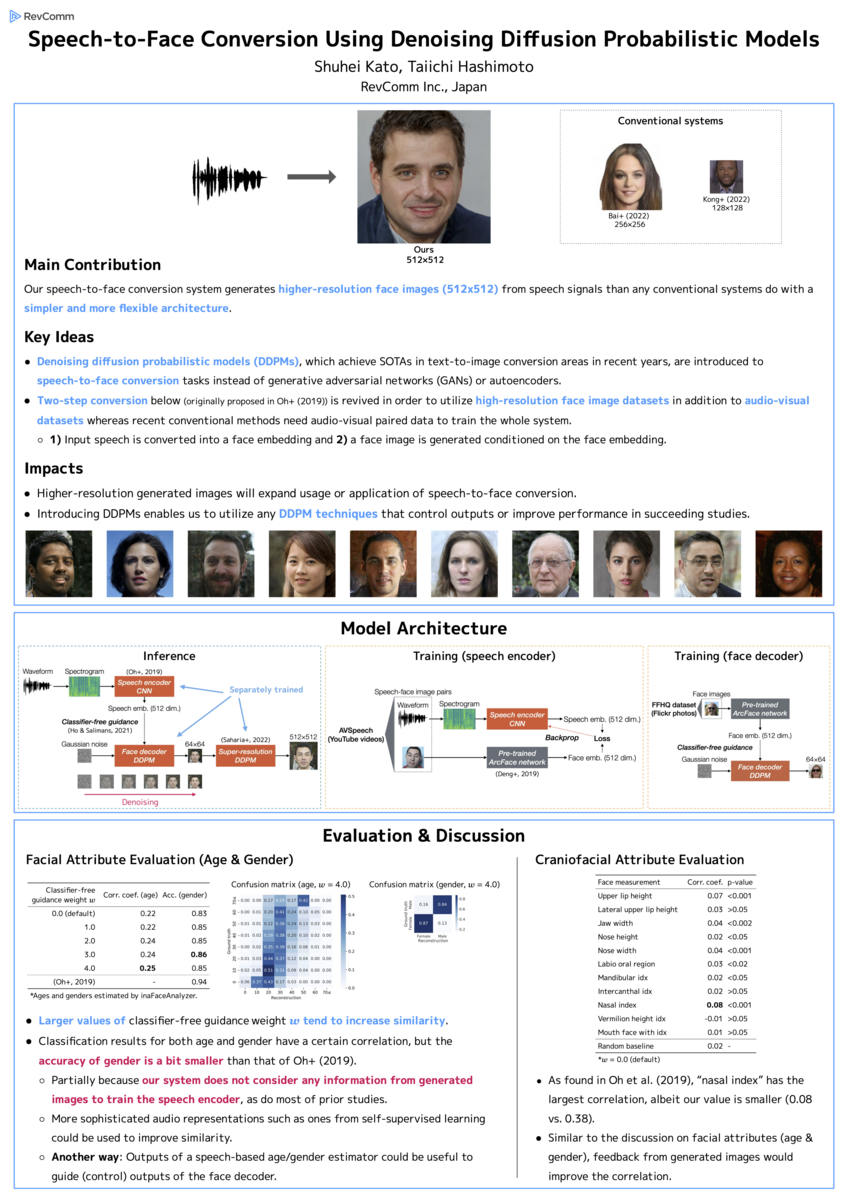
いただいた質問
2時間の発表時間中ほぼ途切れることなく来客があり、以下のような質問をいただきました。
- どのような応用先を考えているか?
- 将来的に、コールセンター等での応用を考えている。カスタマーサポート(特にクレーム対応)などの顔を出せないような場面で、声に適した顔を生成することでコミュニケーションを円滑にするといったことが考えられる。
- 顔画像の生成にはどの程度の時間がかかるか?
- GPUを使って1枚あたり数分かかる。ノイズ除去のステップ数が多いためであり、ステップ数を削減するための技術を応用することで短縮が可能であると考えている。
- データセットはバイアスを内在しているのではないか?内在しているとすれば、何か対処をしているか?
- 今回モデルの訓練および評価に使用したデータセット (AVSpeechおよびFFHQ Dataset) は多様な人々や言語を対象として集められたものであるが、それでも見た目や性別等のバイアスは存在する。今回は特に対処していないが、実用化においては重要な問題だと考えている。
ISCA Speech Synthesis Workshop (SSW)
会議の概要
INTERSPEECHのサテライトワークショップ(付随して開催される小さな会議)として、ISCA Speech Synthesis Special Interest Group (SynSIG) によって開催されているものです。音声合成を専門に取り扱っており、1990年から3年おき、2019年からは隔年で開催されています。
開催期間
2023年8月26日〜28日(INTERSPEECH閉幕の2日後から3日間) 29日に同じ会場でBlizzard Challengeが開催
開催地
グルノーブル・アルプ大学、グルノーブル(フランス)
対象分野
音声合成・音声変換
発表件数
通常発表(査読あり)36件(採択率82.2%) Late Breaking Reports(査読なし)7件
参加人数
110人
会場の様子
発表件数も参加者も小規模であり、すべての発表はシングルトラックで進行されました。


INTERSPEECHとの違い
SSWは音声合成専門のワークショップということで参加人数が小規模でした(110人)。コーヒーブレイクだけでなく昼食も会場内で提供され、休憩時間にもお互い気軽に話しかけられる雰囲気でした。全員が音声合成を専門としているので、話も盛り上がります。

ポスターセッションも枚数が少ないため(1時間半の枠で12枚)、すべてのポスターを見て回ることができました。INTERSPEECHを含む昨今のトップカンファレンスでは発表件数が非常に多いためにすべての発表を見て回るのは不可能ですが、SSWのように分野を絞って開催されるワークショップは違った雰囲気を楽しむことができました。
Blizzard Challenge
SSWとしてのプログラムは8月26日〜28日の開催でしたが、引き続いて29日には同じ会場で音声合成の競技会であるBlizzard Challengeの発表が行われました。Blizzard ChallengeはSSWと同じくSynSIGが主催するイベントで、所定の期間内に、与えられたデータセットを利用して音声合成器を作成し、その品質を競う競技会です。音声合成の技術発展を目的として2005年から毎年開催されており(2022年のみ不実施)、今年の課題はBlizzard Challengeでは初めてとなるフランス語の音声合成でした。
冒頭、今年のBlizzard Challengeの概要と結果の発表が主催者からありました。今年の参加者は18チームで、各チームが提出した音声を元に主催者が聴取実験(音声を多数の人間が聞いて評価する)を実施し、その品質が競われました。品質(人間の音声らしいかどうか)は722人の評価者により、1から5の5段階で評価されました。
結果としては、自然音声(人間の音声)とほとんど同等であるという評価を受けたチームから、自然音声とかなり差があると評価されたチームまで、バラツキがありました。
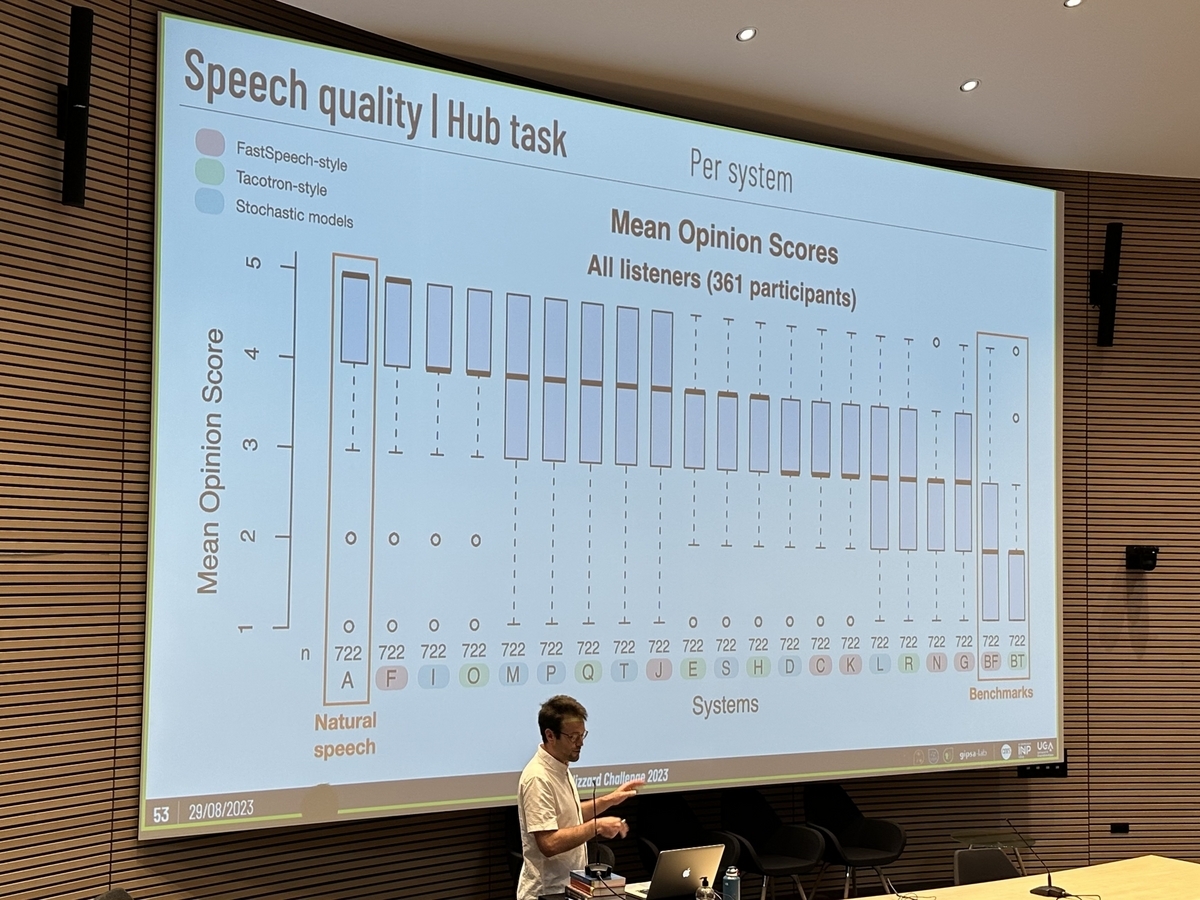
主催者による概要と結果の発表に引き続き、各チームから手法の説明が口頭発表の形式で行われました。上位を獲得したチームの発表にはやはり注目が集まりましたが、あえてユニークな手法で挑戦したチームもあり、成功例・失敗例とも大いに参考になるものでした。
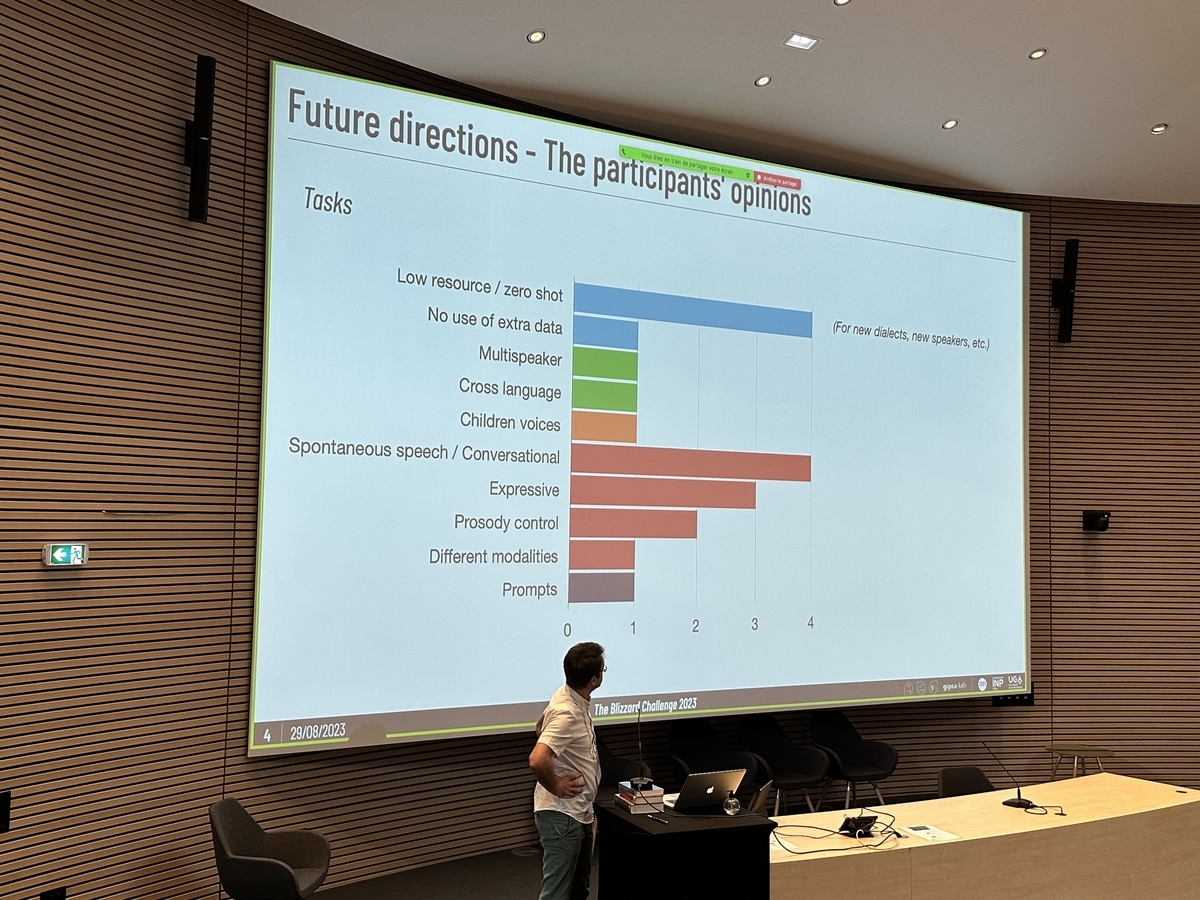
会の最後には、次回のBlizzard Challengeの課題の参考とするために、参加者にアンケートが取られました。実は音声合成の分野では、ここ数年の急速な技術革新により、単一話者・単一言語(特に英語などよく研究されている言語)の原稿を読み上げた音声(読み上げ音声)については、十分な訓練データがあれば自然音声(人間の音声)とほとんど同等の品質が達成できる状況になっています。Blizzard Challengeは音声合成の技術発展を目的としたイベントですから、音声合成コミュニティーとして目指すべき次の方向性を探るべくアンケートが取られたわけです。
アンケートの結果としては、「低資源・ゼロショット」(訓練データが少ない、あるいは未知の話者や方言に対応する)、「(原稿を読み上げた音声との対比としての)自発的・会話的音声※」に多くの票が集まったようです。
※記事執筆時点(2023年11月)では、音声合成モデルの訓練には一般的に「原稿を読み上げた音声(読み上げ音声)」が使われます。これに対して、原稿なしで発話された音声を録音したものを自発的音声 (spontaneous speech)、2人以上の会話を録音したものを会話的音声 (convasational speech) などと呼ぶことがあります。
まとめ
8月下旬に音声処理のトップカンファレンスであるINTERSPEECHで発表するため、また引き続いて行われたISCA Speech Synthesis Workshop (SSW) に参加するためにヨーロッパに出張をしてきました。2,000人の参加者で賑わったINTERSPEECH、110人の参加者でお互いの顔の見えたSSW(そしてBlizzard Challenge)、それぞれに違った楽しみがありました。
INTERSPEECHでの発表では多くの方と有意義な議論をすることができました。今回の発表もチーム内で議論してベストなものを発表しましたが、世界中の研究者と議論することで新たな課題や方向性が見つかるものだということを改めて実感する機会となりました。
RevComm Researchでは、今後も継続的に研究発表を行っていきます。一緒に働きたい方を募集しています。