こんにちは、RevCommでMiiTelの音声解析機能に関する研究開発を担当している石塚です。
石塚賢吉(いしづか けんきち)
プリンシパルリサーチエンジニア。筑波大学大学院博士後期課程卒業。博士(工学)。日本HP株式会社にて通信事業者向けのシステム開発、株式会社ドワンゴで全文検索システムの開発などに従事。2019年12月、株式会社RevComm入社。音声認識、音声感情認識、全文検索システムの研究開発を行なっている。
→ 過去記事一覧
2023年1月に開催された国際会議IEEE Workshop on Spoken Language and Technology (SLT) 2022で発表されたE-Branchformer: Branchformer with Enhanced Merging for Speech Recognition (Kim et al., 2023)*1という論文で、音声認識タスクで高い性能を発揮するE-Branchformerという新しい深層学習モデルが提案されました。論文中では英語の音声コーパスを用いて音声認識精度が評価されていますが、日本語についての評価は行われていません。
End-to-end音声処理ツールキットESPnetのversion 202301からこのE-Branchformerが利用可能となったので、本記事では日本語の音声コーパスである日本語話し言葉コーパス (Corpus of Spontaneous Japanese; CSJ) (Maekawa, 2003)*2でモデル構築および音声認識の精度・スピードの評価を行ってみます。
本記事の内容は以下のとおりです。
E-Branchformerとは
2020年のINTERSPEECHで発表されたConformer: Convolution-augmented Transformer for Speech Recognition (Gulati et al., 2020)*3において、Transformerとconvolutional neural network(CNN; 畳み込みニューラルネットワーク)を組み合わせた深層学習モデルであるConformerが提案されました。Conformerでは、TransformerのMulti-head self attentionでグローバルなコンテキスト情報を捉え、CNNでローカルなコンテキスト情報を捉えます。Conformerをエンコーダーに使用した音声認識モデルは、Transformerの音声認識モデルよりも高い音声認識精度を発揮し、発表時点におけるstate of the art(SOTA; 最高性能のモデル)でした。

このConformerに触発され、2022年のInternational Conference on Machine Learning (ICML) で発表されたBranchformer: Parallel MLP-Attention Architectures to Capture Local and Global Context for Speech Recognition and Understanding (Peng et al., 2022)*4において、並列に分岐する2つのブランチで情報を捉えるBranchformerが提案されました。上記の図のように、ConformerではMulti-head self attentionモジュールの後にCNNで構成されるConvolutionモジュールが続く形となっており、グローバルなコンテキスト情報とローカルなコンテキスト情報を逐次的に扱っていました。一方で、Branchformerでは下記の図のように、1つ目のグローバル抽出ブランチでMulti-head self attentionによりグローバルなコンテキスト情報を捉え、もう1つのローカル抽出ブランチでconvolutional spatial gating unitを利用してローカルなコンテキスト情報を捉えます。そして、後段で各ブランチの出力をマージすることにより、音声認識タスクでConformerと同等の性能を達成しています。なお、Branchformerのマージモジュールでは、をグローバル抽出ブランチによる出力、
をローカル抽出ブランチによる出力としたとき、
と
を連結し、線形射影で次元を削減します。
ここで、は線形射影の学習可能な重みを表します。

そして、E-BranchformerはBranchformerのマージ処理部分を改良したものとして提案されました (Kim et al., 2023)。Branchformerでは、2つのブランチの出力は点別かつ線形に結合されていました。E-Branchformerでは局所的な情報の統合を強化するために、マージモジュールにdepth-wise convolusionによる深さ方向の畳み込みを導入し、2つのブランチからの情報を結合する際にローカルな情報とグローバルな情報を逐次的かつ並列的に組み合わせることで、Branchformerを強化しています。
をグローバル抽出ブランチによる出力、
をローカル抽出ブランチによる出力としたとき、E-branchformerではこれらを下記のようにマージします。
ここで、はdepth-wise convolusion、
は線形射影の学習可能な重みを表します。また、E-Branchformerでは、TransformerやConformerにならい、グローバル抽出ブランチ・ローカル抽出ブランチ・マージモジュールを挟み込む形でfeed forward network (FFN) のモジュールが追加されています。E-Branchformerのエンコーダーの構成は、上記Branchformerのエンコーダーの構成の図のBranchformer blockを下記のE-Branchformer blockに差し替えたものになります。

なお、E-Branchformerの論文中では、LibriSpeech (Panayotov et al., 2015)*5という英語の音声コーパスを利用して音声認識モデルを構築し、音声認識精度の確認が行われています。以下では、日本語の音声コーパスCSJでE-Branchformerの音声認識モデルを構築し、音声認識精度とスピードをConformerの音声認識モデルと比較してみます。
日本語音声コーパスCSJでの利用方法
E-BranchformerはESPNetのv.202301から利用できる状態になっていますが、日本語の音声コーパスに対応したレシピはまだ存在しない状態です。そこで、英語の音声コーパスであるLibriSpeechのレシピの中にあるE-Branchformerの設定を、日本語音声コーパスCSJのレシピにコピーして利用します。
ESPNetのv.202301の学習環境とCSJのセットアップが完了した状態から、E-Branchformerを用いた音声認識モデルを構築する手順は下記のとおりです。
- LibriSpeechのレシピの中にあるE-Branchformerの設定ファイルtrain_asr_e_branchformer.yamlをCSJレシピのconfディレクトリの配下にコピーする
- CSJレシピの学習スクリプトの学習設定ファイルの参照先をasr_config=conf/train_asr_e_branchformer.yaml にする
- run.shを実行する
得られたモデルの音声認識の精度とスピード
モデルの学習
本実験では、NVIDIA V100を4つ搭載したABCIのrt_Fノードで音声認識モデルの学習を行います。デフォルトの学習設定のバッチサイズではout of memory (OOM) が発生してしまうので、batch_binsの設定を1/8 (140,000,000 / 8 = 17,500,000) にしました。また、言語モデルは使わないこととします。
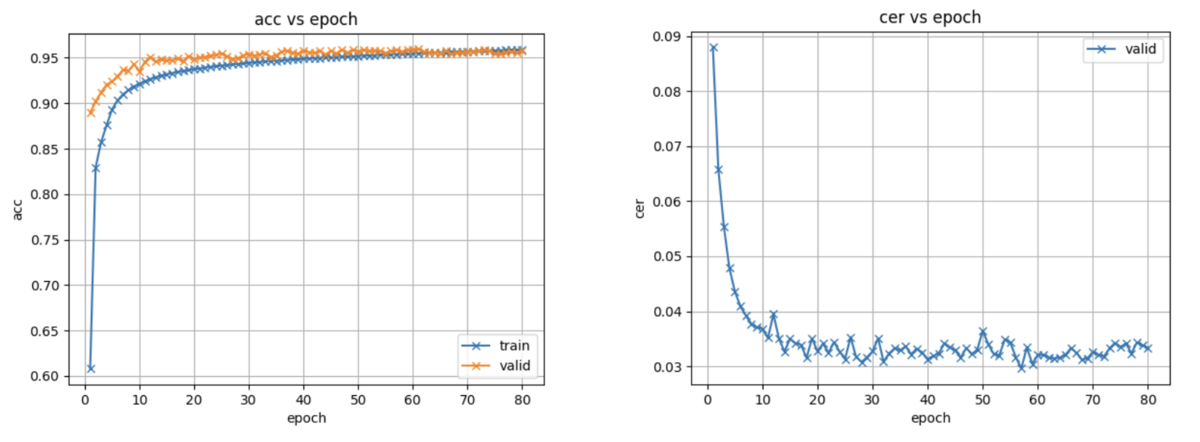
CSJの学習データを用いてデフォルトの80エポックまで音声認識モデルの学習を行ったところ、学習曲線は下記のようになりました。なお、音声認識モデルの学習には約130時間かかりました。
音声認識精度の評価
上記で学習したE-Branchformerの音声認識モデルを用いて、言語モデルなしでCSJのテストセットを音声認識したときのCharacter Error Rate(CER; 文字誤り率)と、学習済のConformerのモデルを用いて、同じく言語モデルなしでCSJのテストセットを音声認識したときのCERを下記の表に示します (%)。表を見ると、E-BranchformerのほうがConformerよりCERが0.3から0.7ポイント低く、音声認識精度がよいことがわかります。
| テストセット | E-Branchformer | Conformer |
|---|---|---|
| eval1 | 3.8 | 4.5 |
| eval2 | 2.9 | 3.2 |
| eval3 | 3.2 | 3.5 |
音声認識スピードの評価
次に、NVIDIA A10を搭載するAWSのg5.xlargeインスタンスを用いて、CSJのeval1からeval3のテストセットをGPUで音声認識するときのスピードを下記のReal Time Factor (RTF) の指標で確認しました。
なお、batch_sizeは1、beam_sizeは20としました。E-BranchformerとConformerの音声認識モデルでCSJのテストセットを音声認識したときのRTFを下記の表に記載します。表から分かるとおり、認識スピードはConformerよりE-Branchformerのほうが少し遅い結果となりました。
| E-Branchformer | Conformer |
|---|---|
| 0.297 | 0.268 |
まとめ
本記事では、E-Branchformerについて簡単に紹介し、日本語の音声コーパスCSJでE-Branchformerの音声認識モデルを構築し、認識精度および認識スピードについてConformerの音声認識モデルと比較しました。結果として、E-Branchformerモデルの方が、Conformerモデルより高い精度で音声認識ができることがわかりました。一方で、今回構築したE-Branchformerの音声認識モデルは、Conformerの音声認識モデルよりも音声認識処理に少し時間がかかりました。
なお、今回の実験では、E-BranchformerをAttentionベースのEncoder-Decoder音声認識モデルのエンコーダーに適用しましたが、E-Branchformerはconnectionist temporal classification (CTC) やTransducerなどのリアルタイム処理に適した高速な音声認識モデルに適用することもできるようです。認識スピードを重視する場合は、CTCやTransducerとの組み合わせを試してみるとよいかもしれません。
*1:Kim, K., Wu, F., Peng, Y., Pan, J., Sridhar, P., Han, K. J., & Watanabe, S. (2023). E-Branchformer: Branchformer with Enhanced Merging for Speech Recognition. Proc. IEEE Spoken Language Technology Workshop (SLT), 84–91.
*2:Maekawa, K. (2003). Corpus of Spontaneous Japanese: Its Design and Evaluation. Proc. ISCA/IEEE Workshop on Spontaneous Speech Processing and Recognition (SSPR), 7–12.
*3:Gulati, A., Qin, J., Chiu, C.-C., Parmar, N., Zhang, Y., Yu, J., Han, W., Wang, S., Zhang, Z., Wu, Y., & Pang, R. (2020). Conformer: Convolution-Augmented Transformer for Speech Recognition. Proc. INTERSPEECH, 5036–5040.
*4:Peng, Y., Dalmia, S., Lane, I., & Watanabe, S. (2022). Branchformer: Parallel MLP-Attention Architectures to Capture Local and Global Context for Speech Recognition and Understanding. Proc. International Conference on Machine Learning (ICML).
*5:Panayotov, V., Chen, G., Povey, D., & Khudanpur, S. (2015). LibriSpeech: An ASR Corpus Based on Public Domain Audio Books. Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 5206–5210.