概要
こんにちは、RevCommでMiiTelの音声解析機能に関する研究開発を担当している石塚です。前回のRevComm Tech Blogにて、2023年時点でSOTAの精度であったE-Branchformer[1]を利用して日本語の音声認識モデルを構築する記事について書きました。
前回の実験において、E-Branchformerで構築したモデルは、精度ではConformerで構築したモデルより優れていましたが、スピードはConformerで構築したモデルよりも少し遅いものとなっていました。音声認識システムの実運用を考えると、音声認識のスピードは非常に重要です。
そこで今回は、高速な非自己回帰型のアーキテクチャでE-Branchformerの音声認識モデルを構築し、どの程度のスピードで音声認識可能かを確かめたいと思います。
石塚賢吉(いしづか けんきち)
プリンシパルリサーチエンジニア。筑波大学大学院博士後期課程卒業。博士(工学)。日本HP株式会社にて通信事業者向けのシステム開発、株式会社ドワンゴで全文検索システムの開発などに従事。2019年12月、株式会社RevComm入社。音声認識、音声感情認識、全文検索システムの研究開発を行なっている。
→ 過去記事一覧
非自己回帰型の音声認識モデルについて
E2E音声認識モデルは、大きく分けると自己回帰モデルと非自己回帰モデルに分類できます。前回の実験で構築したモデルは、 EncoderにE-Branchformer、DecoderにTransformerを用いたものであり、Attention Encoder-Decoderと呼ばれる自己回帰型に分類されるモデルでした。このタイプのモデルでは、下記の図のように過去の出力トークンに基づいて現在の出力トークンを生成するため、N個のトークンの生成のためにN回の計算が必要になります。

一方、非自己回帰型の音声認識モデルでは、音響特徴量のシーケンスからテキストトークンのシーケンスを直接生成し、一定の計算コストで処理できるため、高速に推論することが可能です。ESPnetでは、Mask-CTC[2]と呼ばれる非自己回帰型の音声認識モデルを利用することができます。
Mask-CTCでは、下記のように入力された音声からEncoderで音響特徴量を抽出し、Connectionist Temporal Classification(CTC)という手法で、音響特徴量から発話テキストを直接推定します。CTCでは、Blankラベルトークンを導入することで、長さが大きく異なる音響特徴量シーケンスとテキストのトークンのシーケンスとの対応関係を表現しています。さらにMask-CTCでは、CTCの出力トークンのうち信頼度の低いトークンをマスキングし、TransformerのMasked Language Model(MLM)のMask-Predictionを用いて誤りを修正することで、音声認識精度を改善します。Mask-CTCのアルゴリズムの詳細については、論文 を参照ください。
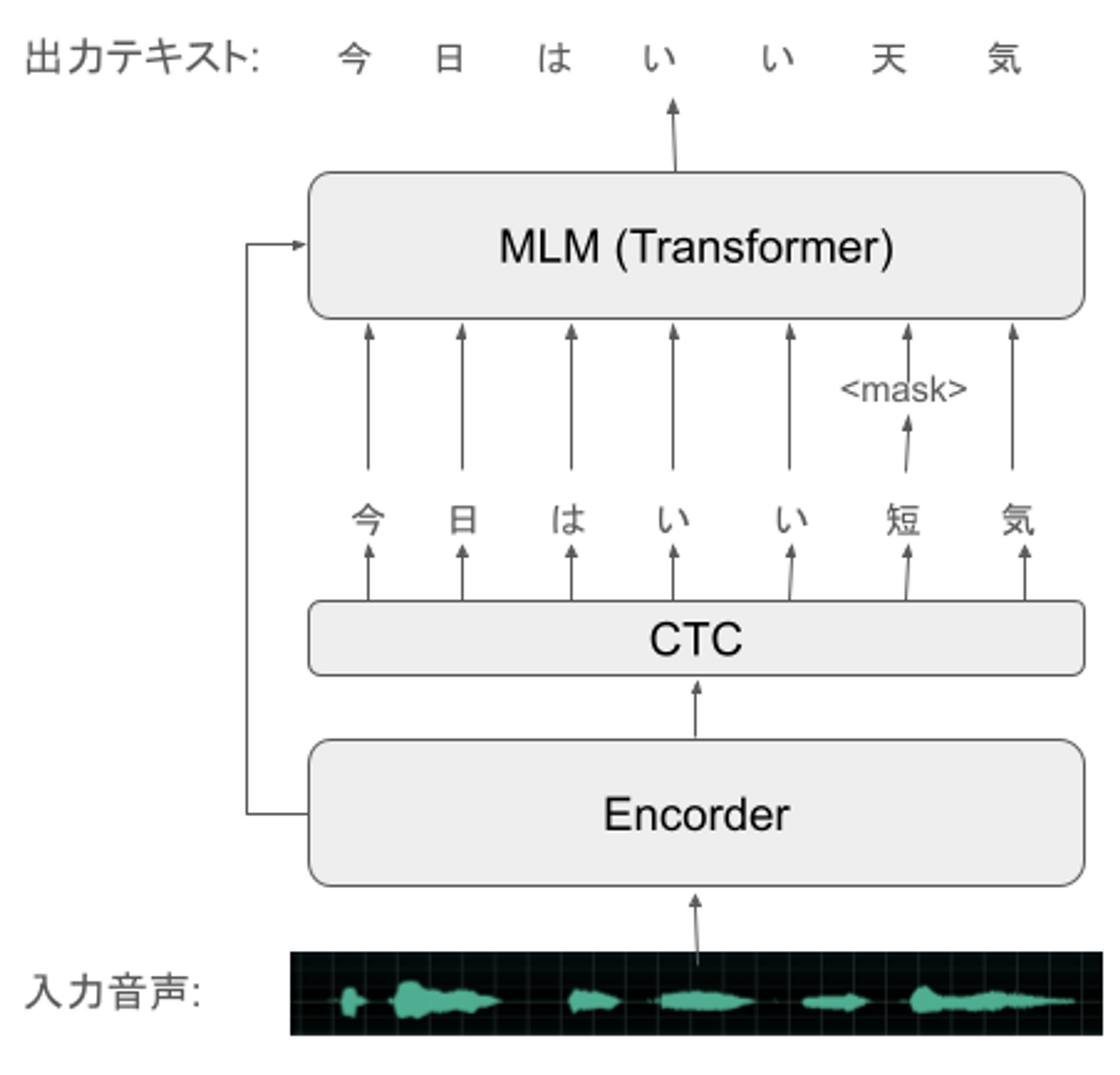
今回は、E-BranchformerでMask-CTCの非自己回帰型の音声認識モデルを構築したいので、EncoderにE-Branchformer、DecoderにCTC、およびMLM Decoderを用いて、音声認識モデルを構築します。
実験方法
- 前回と同様にCSJデータセットでモデルを構築します。
E-BranchformerはESPNetのv.202301から利用できる状態になっていますが、Mask-CTCと組み合わせて利用するレシピはまだ存在しない状態です。そこで、WSJのMask-CTCのレシピの学習の設定ファイルと、LibriSpeechのE-Branchformerのレシピの学習の設定ファイルを元に、EncoderにE-Branchformer、DecoderにCTCとMLMを利用するモデルの学習の設定ファイルを作成します。今回作成した学習の設定ファイルは下記になります。
train_asr_e_branchformer_small_mask_ctc.yaml
batch_type: folded batch_size: 32 accum_grad: 8 max_epoch: 300 patience: none init: none best_model_criterion: - - valid - cer_ctc - min keep_nbest_models: 10 # specify model type as "maskctc" model: maskctc model_conf: ctc_weight: 0.3 lsm_weight: 0.1 length_normalized_loss: false use_amp: true unused_parameters: true num_workers: 4 encoder: e_branchformer encoder_conf: output_size: 256 attention_heads: 4 attention_layer_type: rel_selfattn pos_enc_layer_type: rel_pos rel_pos_type: latest cgmlp_linear_units: 3072 cgmlp_conv_kernel: 31 use_linear_after_conv: false gate_activation: identity num_blocks: 12 dropout_rate: 0.1 positional_dropout_rate: 0.1 attention_dropout_rate: 0.1 input_layer: conv2d layer_drop_rate: 0.1 linear_units: 1024 positionwise_layer_type: linear macaron_ffn: true use_ffn: true merge_conv_kernel: 31 # Masked Language Model (MLM)-based decoder decoder: mlm decoder_conf: attention_heads: 4 linear_units: 2048 num_blocks: 6 dropout_rate: 0.1 positional_dropout_rate: 0.1 self_attention_dropout_rate: 0.1 src_attention_dropout_rate: 0.1 optim: adam optim_conf: lr: 0.002 weight_decay: 0.000001 scheduler: warmuplr scheduler_conf: warmup_steps: 15000 num_att_plot: 0 specaug: specaug specaug_conf: apply_time_warp: true time_warp_window: 5 time_warp_mode: bicubic apply_freq_mask: true freq_mask_width_range: - 0 - 27 num_freq_mask: 2 apply_time_mask: true time_mask_width_ratio_range: - 0. - 0.05 num_time_mask: 5- ESPNet v.202301の学習環境とCSJのセットアップが完了した状態から、E-Branchformerを用いた音声認識モデルを構築する手順は下記のとおりです。
- 作成した学習の設定ファイルtrain_asr_e_branchformer_small_mask_ctc.yamlをCSJレシピのconfディレクトリに配置する
- CSJレシピの学習スクリプトの学習設定ファイルの参照先をasr_config=conf/train_asr_e_branchformer_small_mask_ctc.yaml にする
- Mask-CTCの推論の設定ファイル をCSJレシピのconfディレクトリの配下にコピーする。CSJレシピの推論設定ファイルの参照先 をinference_config=conf/inference_asr_maskctc.yaml にする。
./asr.shで--use_maskctc trueを設定して run.shを実行する
得られたモデルの音声認識の精度とスピード
モデルの学習
ABCIのrt_Fインスタンス (NVidia V100*4)でCSJの学習データを用いて50エポックまで音声認識モデルの学習を行ったところ、CSJのValidセットのCharacter Error Rate(CER; 文字誤り率)とEpochの関係は下記のようになりました。
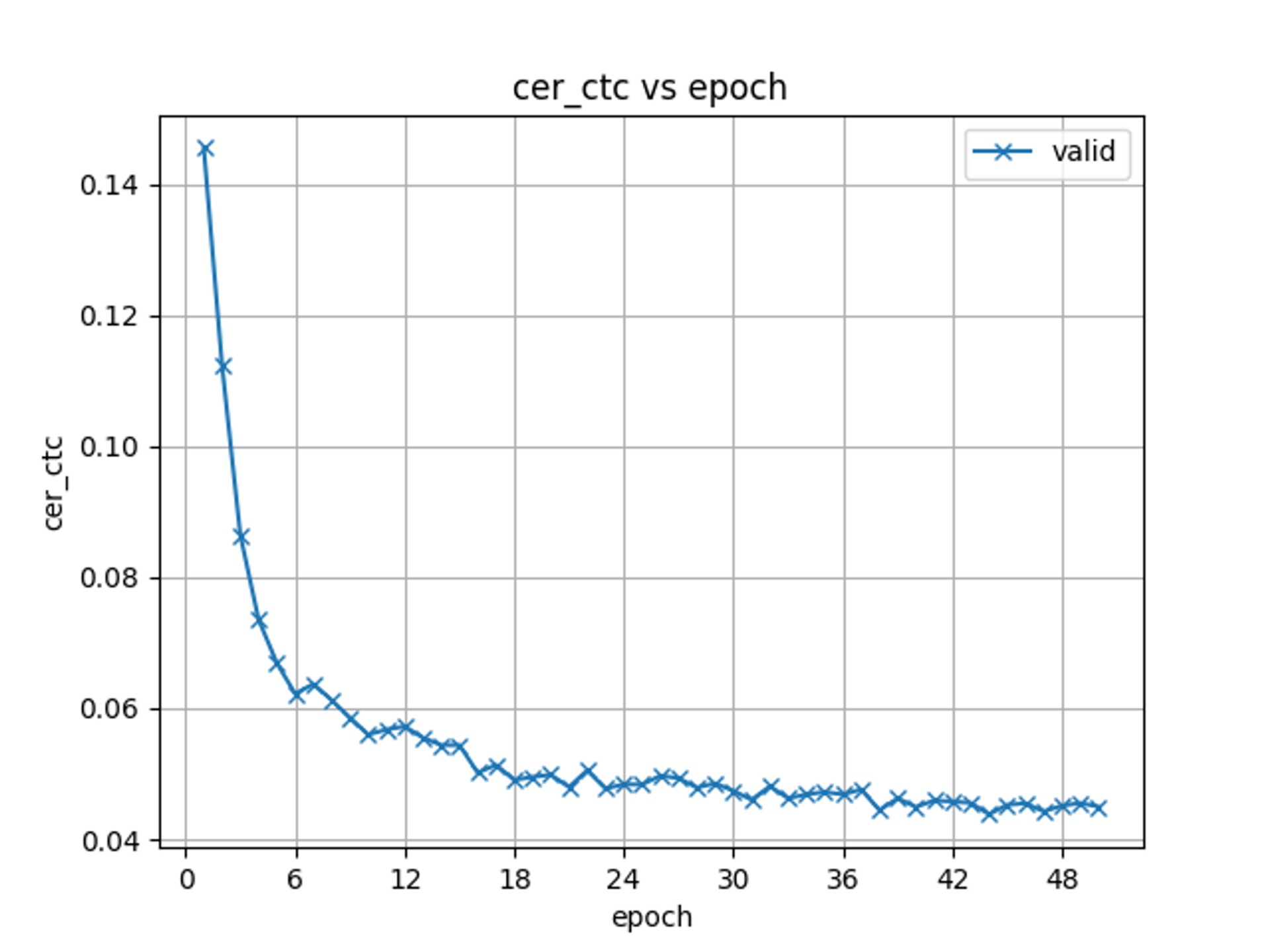
音声認識精度の評価
前回学習した、EncoderがE-BranchformerでDecoderがTransformerのモデルと、今回学習したEncoderがE-BranchformerでDecoderがCTC・MLMのモデルで、CSJのテストセットを音声認識したときのCERを下記の表に示します (%)。Decoderの列が CTCの行は、CTCの出力トークンそのままの精度で、 CTC+MLM の行は、CTCの出力トークンをMLMのMask-Predictionで修正した時の精度です。
なお、比較対象として、Mask-CTCの論文 にあるEncoderがTransformerでDecoderがCTCとMLMの構成のモデルを50Epochまで学習したものと、EncoderとDecoderの両方がTransformerのプリトレインドモデルを用意しました。なお、DecoderがCTC・MLMのモデルは、Mask-CTCの論文に合わせて、Encoderの中間層のニューロンの数が256となっていることにご注意ください。また、DecoderがTransformerの音声認識モデルでは、言語モデルは利用していません。
| Encoder | Decoder | Type | CER(eval1) | CER(eval2) | CER(eval3) |
|---|---|---|---|---|---|
| E-Branchformer (Output:512) | Transformer | 自己回帰型 | 3.8 | 2.9 | 3.2 |
| E-Branchformer (Output:256) | CTC | 非自己回帰型 | 4.5 | 3.2 | 3.8 |
| E-Branchformer (Output:256) | CTC+MLM (p=0.9, it=5) | 非自己回帰型 | 4.5 | 3.2 | 3.8 |
| Transformer (Output:512) | Transformer | 自己回帰型 | 4.9 | 3.8 | 3.8 |
| Transformer (Output:256) | CTC | 非自己回帰型 | 6.2 | 4.6 | 5.4 |
| Transformer (Output:256) | CTC+MLM (p=0.9, it=5) | 非自己回帰型 | 6.2 | 4.4 | 5.3 |
表を見ると、E-Branchformer の非自己回帰型の音声認識モデルは、精度において自己回帰型のE-Branchformerの音声認識モデルには及ばないようです。しかし、E-Branchformer の非自己回帰型の音声認識モデルは、Transformerの自己回帰型の音声認識モデルよりも良い精度となっています。なお、今回の実験では、EncoderがTransformerの非自己回帰型の音声認識モデルでは、MLMによる修正で精度が上がりましたが、EncoderがE-Branchformerの非自己回帰型の音声認識モデルについては、MLMによる修正を行なっても精度が向上しませんでした。
音声認識スピードの評価
次に、CSJのeval1からeval3のテストセットをCPUまたはGPUで音声認識するときのスピードを下記のReal Time Factor (RTF) と、Inverse Real Time Factor (iRTF) の指標で確認しました。iRTFは、1秒間で何秒の長さの音声を認識できるかを表す指標です。
CPUでのデコードについて
AWSのc5.xlargeのCPUで1Threadでデコードした時のRTFとiRTFを下記の表に示します。なお、DecoderがTransformerの自己回帰型のモデルでは、beam size=2でデコードしています。
| Encoder | Decoder | Type | RTF | iRTF |
|---|---|---|---|---|
| E-Branchformer (Output:512) | Transformer | 自己回帰型 | 2.291 | 0.436 |
| E-Branchformer (Output:256) | CTC | 非自己回帰型 | 0.664 | 1.506 |
| E-Branchformer (Output:256) | CTC+MLM (p=0.9, it=5) | 非自己回帰型 | 0.805 | 1.242 |
| Transformer (Output:512) | Transformer | 自己回帰型 | 0.383 | 2.611 |
| Transformer (Output:256) | CTC | 非自己回帰型 | 0.031 | 32.258 |
| Transformer (Output:256) | CTC+MLM (p=0.9, it=5) | 非自己回帰型 | 0.042 | 23.810 |
EncoderがE-Branchformerの自己回帰型の音声認識モデルの音声認識スピードは、RTFの値が1以上となってしまいました。また、EncoderがE-Branchformerの非自己回帰型の音声認識モデルは、EncoderがTransformerの非自己回帰型の音声認識モデルよりも音声認識スピードが遅いようでした。E-Branchformerのエンコーダは、CPUでは計算処理が重いようです。
GPUでのデコードについて
NVIDIA A10を搭載するAWSのg5.xlargeインスタンスを用いて、デコードした時のRTFを下記の表に示します。なお、バッチデコードはしていません。
| Encoder | Decoder | Type | RTF | iRTF | CPUに対するスピード倍率 [iRTF(GPU)/iRTF(CPU)] |
|---|---|---|---|---|---|
| E-Branchformer(Output:512) | Transformer | 自己回帰型 | 0.235 | 4.255 | 9.749 |
| E-Branchformer(Output:256) | CTC | 非自己回帰型 | 0.011 | 90.909 | 60.364 |
| E-Branchformer(Output:256) | CTC+MLM (p=0.9, it=5) | 非自己回帰型 | 0.013 | 76.923 | 61.923 |
| Transformer(Output:512) | Transformer | 自己回帰型 | 0.198 | 5.051 | 1.934 |
| Transformer(Output:256) | CTC | 非自己回帰型 | 0.009 | 111.111 | 3.444 |
| Transformer(Output:256) | CTC+MLM (p=0.9, it=5) | 非自己回帰型 | 0.011 | 90.909 | 3.818 |
GPUによるデコードでは、E-Branchformerの非自己回帰型の音声認識モデルの音声認識スピードがCPUの時と比べ大幅(約62倍)に向上し、Transformerの非自己回帰型の音声認識モデルに近いスピードとなっています。非自己回帰型の音声認識モデルは、GPUで音声認識した時に大きくスピードが向上するようです。一方で、自己回帰型の音声認識モデルは、GPUで音声認識しても、非自己回帰型の音声認識モデルの時ほど音声認識スピードが向上しないようです。原因は深く追っていませんが、TransformerのDecoderでの自己回帰的な処理とBeamsearchなどのポストプロセスの処理がボトルネックになっているものと思われます。
まとめ
本記事では、高速な非自己回帰型の音声認識モデルである、E-BranchformerのMaskCTCの音声認識モデルを構築し、音声認識精度とスピードを確認しました。E-BranchformerのMaskCTCの音声認識モデルは、非自己回帰型の音声認識モデルでありながら、Transformerの自己回帰型の音声認識モデルよりも精度が高く、GPUを用いた時に高速に音声認識できることがわかりました。
なお、本記事では触れませんでしたが、今回構築した非自己回帰型の音声認識モデルをONNXなどの推論エンジンの形式に変換することで、さらに音声認識スピードを向上できるようでした。また、今回の実験でのGPUによる音声認識はバッチデコードになっていませんでしたが、おそらくバッチデコードを行うことで、さらなる高速化が期待できます。