Introduction
Hello, I'm Santoso, and I work as a Research Engineer at RevComm Research Team. Today, I will introduce our recent study on improving domain-specific vocabulary (DSV) recognition in our products using generative error correction (GEC).
Automatic speech recognition (ASR) and domain-specific vocabulary (DSV) recognition
ASR is a business essential, powering platforms like our AI-powered IP phone, MiiTel. While MiiTel already helps businesses improve sales and customer service with instant transcripts and in-depth analytics, we must overcome a key challenge to fully unlock its power: the accurate recognition of DSV. DSV includes industry-specific jargon, company names, and product terms that general ASR models often fail to recognize because they are rare or absent in their training data. Such errors can have real-world consequences, like a customer service representative misinterpreting a client's request or a sales team failing to log key details. To address this, our research moves beyond traditional ASR limitations and develops a new, scalable approach to automatically identify and correct these transcription errors.
The problem with traditional approaches
Improving DSV recognition has long been technically challenging since the traditional method involving ASR model fine-tuning on a large dataset of specialized vocabulary struggles with scalability. Fine-tuning requires costly human labor to create and annotate extensive DSV dictionaries for every new domain, making it a major barrier for businesses operating across diverse fields and highlighting the need for a more efficient, scalable solution.
Our approach: A scalable solution with generative error correction (GEC)
Our research tackles this problem with GEC, a powerful post-processing technique that leverages large language models (LLMs) to automatically identify and correct transcription errors using conversational context. This method avoids costly manual dictionary creation.
GEC is particularly advantageous for DSV because the LLM can infer the correct term from the surrounding context. Unlike simple word-swapping methods, GEC models use the entire sentence context, similar to a human proofreader, to generate a corrected version. This allows us to efficiently and scalably fix errors without manually updating the entire ASR model for every new domain.
By focusing on this scalable error correction method, we aim to ensure that MiiTel delivers the highest transcription quality, no matter the domain. This will allow businesses to capture every critical detail from their conversations, providing deeper insights and a superior customer experience.
How do we measure DSV recognition performance?
To solve the DSV problem, we needed a precise way to measure our progress using the following metrics:
- Character Error Rate (CER): We measure the total number of errors in the full transcript to give us a baseline of the model's general performance.
- Match Accuracy: We use a binary metric to check if the specific DSV was transcribed perfectly for the most critical words.
- Match Ratio: We use this metric to quantify how close a misrecognized DSV is to the correct term, helping us understand the nature of the error. For example: CDMA2000 transcribed as CTNA2000 has a match ratio of 0.75, with differences in the second and third letter.
By using these metrics together, we can prove our model isn't just getting better in general, but specifically mastering the specialized language that matters most.
How does GEC improve DSV performance? Our experiments
Our experimental setup and methodology
To prove the effectiveness of our approach, we defined our own dataset from operator-customer conversations in MiiTel from three key domains: finance, human resources, and real estate. We created this specific dataset to verify that our method would be useful for our product's specific, real-world conversational data.
Our dataset is divided into utterances containing annotated DSV and those known to contain no DSV. Our core experimental setup includes MiiTel's internal ASR engine as the primary baseline, alongside other leading commercial models as ASR output references. Our core methodology revolves around GEC post-processing with LLMs to correct transcription errors. Given that our target language is Japanese, where a single pronunciation can have multiple meanings depending on context, we explored several methods to leverage both the transcribed text and its pronunciation.
Our proposed methods
We tested several methods, each designed to tackle the DSV problem from a different angle:
- Prompt-based Correction: Our initial approach used simple prompts to ask an LLM to correct a transcription, with another ASR result as a reference. This serves as a baseline for how a simple LLM-only solution performs.
- Context-Informed Correction: Recognizing that context is key, we developed methods that provided the LLM with additional information, such as the conversation's domain (e.g., "This conversation is about finance"). This was intended to help the LLM better focus on the relevant vocabulary.
- The Two-Step Method: Our most advanced approach was a two-step process that proved to be the most effective. First, we identify a list of potential DSVs by comparing the outputs of multiple ASR models. Second, we present the LLM with a list of plausible sentences, including our identified candidates, and ask it to select the most reasonable one. This method corrects only the specific segment with the DSV, preserving the original sentence's fillers and contents.
Our findings
Simple GEC: Is it enough?
The short answer is no; correcting an entire sentence with simple GEC can harm the original, well-recognized parts of the transcript.
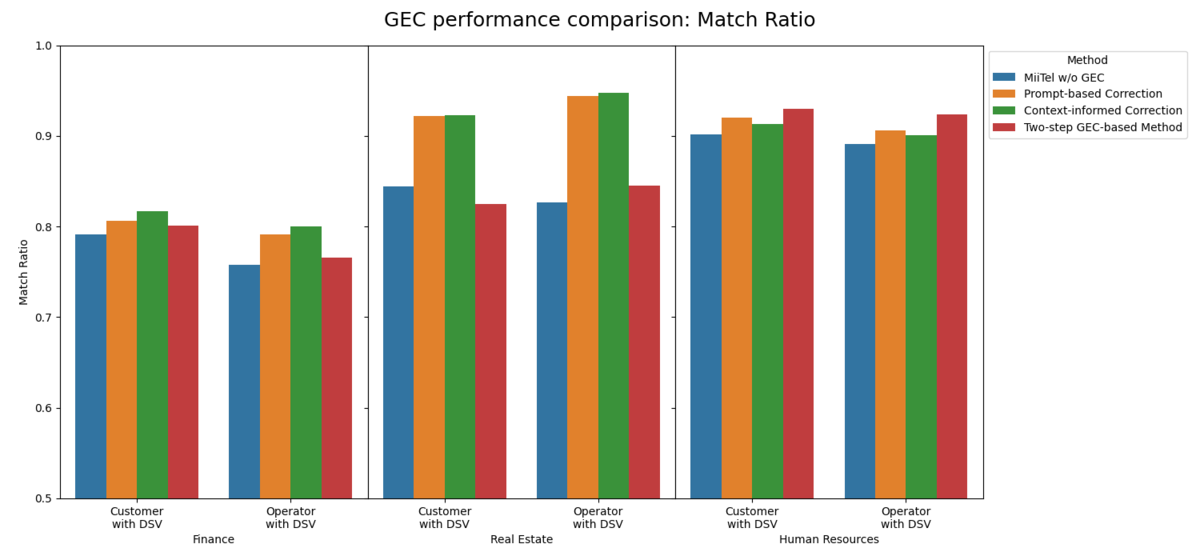
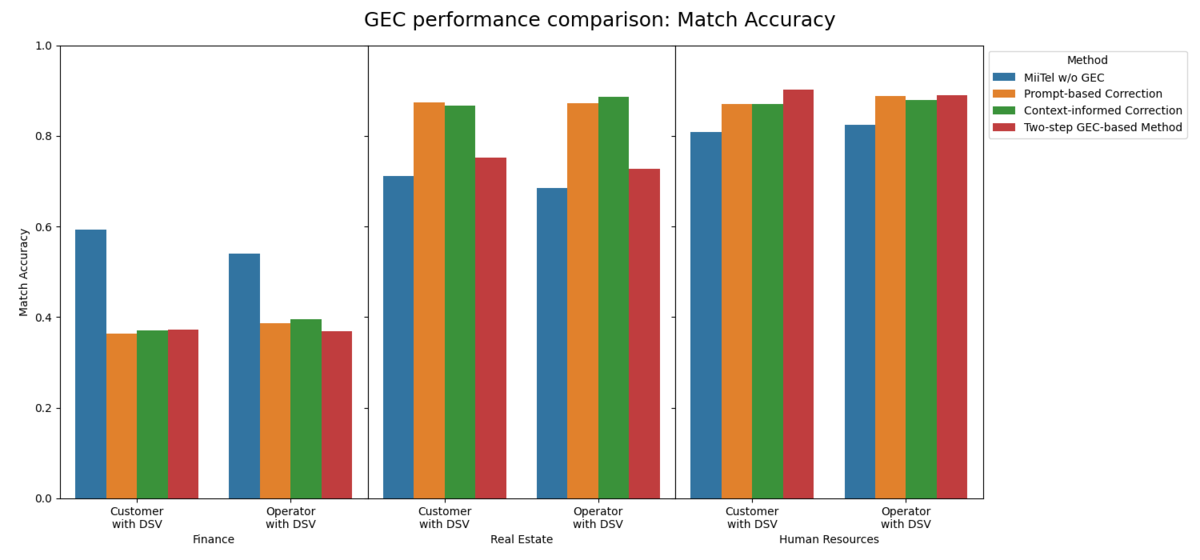
As illustrated in the figures, our first two methods (simple prompt-based and context-informed correction) did show some improvement in DSV Match Ratio and Accuracy compared to MiiTel’s ASR without GEC. However, this came at a high cost of CER degradation. Directly correcting the full ASR transcript, even with multiple references and simple context provided, ends up introducing more errors than it fixed—a phenomenon known as "overcorrection."
The two-step correction method dramatically improves overall transcription quality by achieving a remarkably low CER and significantly outperforming all ASR baselines. By identifying only the segments likely to contain a DSV and correcting just those parts, our method preserved the original transcription's integrity, allowing us to dramatically lower the overall CER.
Despite the overall improvement, our two-step method does present a slight tradeoff in DSV recognizability, which is slightly lower than that of the simple prompt-based method. This is a small, acceptable trade-off given the dramatic improvement in overall CER, making the two-step method the most practical and robust solution for our use case. We also observed some performance differences across domains, suggesting the varying challenges of ASR and LLM in recognizing DSV from different fields.
Analysis: Beyond the numbers
While our metrics provide the proof, a look at real-world error types shows the true impact and precision of our methods. Let's examine a specific case from the finance domain where our internal ASR struggled with a key term such as "NISA".
A term like "NISA" poses a unique challenge because it is pronounced similarly to common Japanese homophones. For example, our baseline ASR models often misrecognized this term as the homophone "入社" ("nyuusha", "joined the company") or completely misinterpreted it as a related, yet incorrect, term like "新任者" ("shinninsha", "new person"). Simple GEC methods that correct the entire sentence successfully fixed these types of errors by leveraging the broader knowledge of the LLM.
The crucial advantage of our two-step GEC method lies in its precision; it targets only the specific segment where an error is likely to have occurred. For a challenging term like "NISA," our method correctly identified the problematic segment and provided a list of plausible candidates to the LLM, leading to a successful correction. While this approach proved highly effective in maintaining overall transcription quality, we did observe a limitation: the method's accuracy is only as good as the candidates provided to the LLM. In some cases, the correct term (such as a unique, compound DSV) was not generated as a candidate, presenting a clear opportunity for future work. This highlights a core strength of our approach, which lies on its ability to solve a major problem while clearly identifying its own remaining challenges.
Challenges and limitations
While GEC significantly improves ASR performance, our research identified several key limitations that require consideration.
First, GEC is highly dependent on the quality of the initial ASR output. When a model's transcription drastically changes a speaker's style or paraphrases an utterance, the LLM can lose the necessary context, making correction difficult.
Furthermore, we found that LLMs, despite their vast knowledge, don't know every DSV. This means some very rare or newly updated vocabulary may still require external knowledge. This also highlights a core trade-off, where achieving high accuracy with GEC involves a slight increase in computational overhead and prompt engineering costs.
Finally, our findings reveal a language-specific challenge rooted in the existence of different notations or similar readings in Japanese. Other than the ones mentioned in our experiments, there are subtle differences that would be considered the “correct” terminology, such as 振り込み vs 振込 (both read as “furikomi”). We found that some of the subtle decreases in our two-step method's DSV recognition accuracy were caused by these notational differences, even when the LLM correctly identified the word's pronunciation and the intended word. Given the significant CER improvement, this trade-off is a reasonable cost for maintaining overall transcription quality.
Conclusions and future work
This research demonstrates that GEC is a highly effective and scalable post-processing step for improving DSV recognition. By leveraging GEC, we've shown that specialized ASR solutions are not only possible but essential for platforms like MiiTel, where accuracy in specialized terminology is critical for sales, customer service, and data analysis. We believe GEC has the potential to transform ASR from a general utility into a powerful, industry-specific tool.
The findings and limitations we've identified are clear signposts for future research that will expand the capabilities of our method. Our work is now expanding to explore how these methods can be combined with other ASR architectures and applied to more diverse and niche domains. We are particularly excited to tackle the challenging task of recognizing industry-specific jargon and product names, which are frequently misrecognized due to their unconventional naming and rarity. The principles of our two-step GEC-based method can be applied to languages beyond Japanese, such as English. We look forward to exploring these opportunities to create a more versatile, multilingual system that continues to push the boundaries of ASR accuracy.