
はじめに
この記事は『対話要約研究の最前線 前編 〜データセットと評価指標の紹介〜』の続きです。
RevCommは電話営業や顧客応対の通話を支援するAI搭載型のIP電話「MiiTel」を提供しています。 この製品は、通話の文字起こしを保存する機能を備えており、RevCommは数千時間の対話データに接しています。
この対話データに対する支援の1つとして対話要約が考えられます。対話要約とは、入力された対話から、その主要な概念を含む、より短い文書(要約)を自動的に作成することです。 ユーザは、要約を作成する手間が省けたり、あるいは要約を読むことで対話の概要をより早く理解できるなどの利点があります。
本記事では、はじめに対話要約の手法の概要を書き次に近年の研究をいくつかご紹介します。
対話要約手法の概要
ここでは対話要約の手法の概要を説明します。今回の記事の趣旨は、最近の研究をいくつか紹介することなので、こちらについては簡単な説明にとどめます。
要約手法の分類方法は何種類かありますが、ここでは抽出的要約と抽象的要約の2つの分類方法に従います。要約を制限するためのクエリや、対話状態の管理方法についてはここでは触れません。また、要約手法ではありませんが、与えられた対話の概要を得るために用いられる手法を紹介します。
抽出的要約
入力文書の一部を切り出して要約文を作成する方法です。この手法における重要な課題は、入力文書のどの部分を切り出すのかを検討することです。例えば、重要度の高い文を選んだり、特定のトピックの文を選んだりする方法があります。
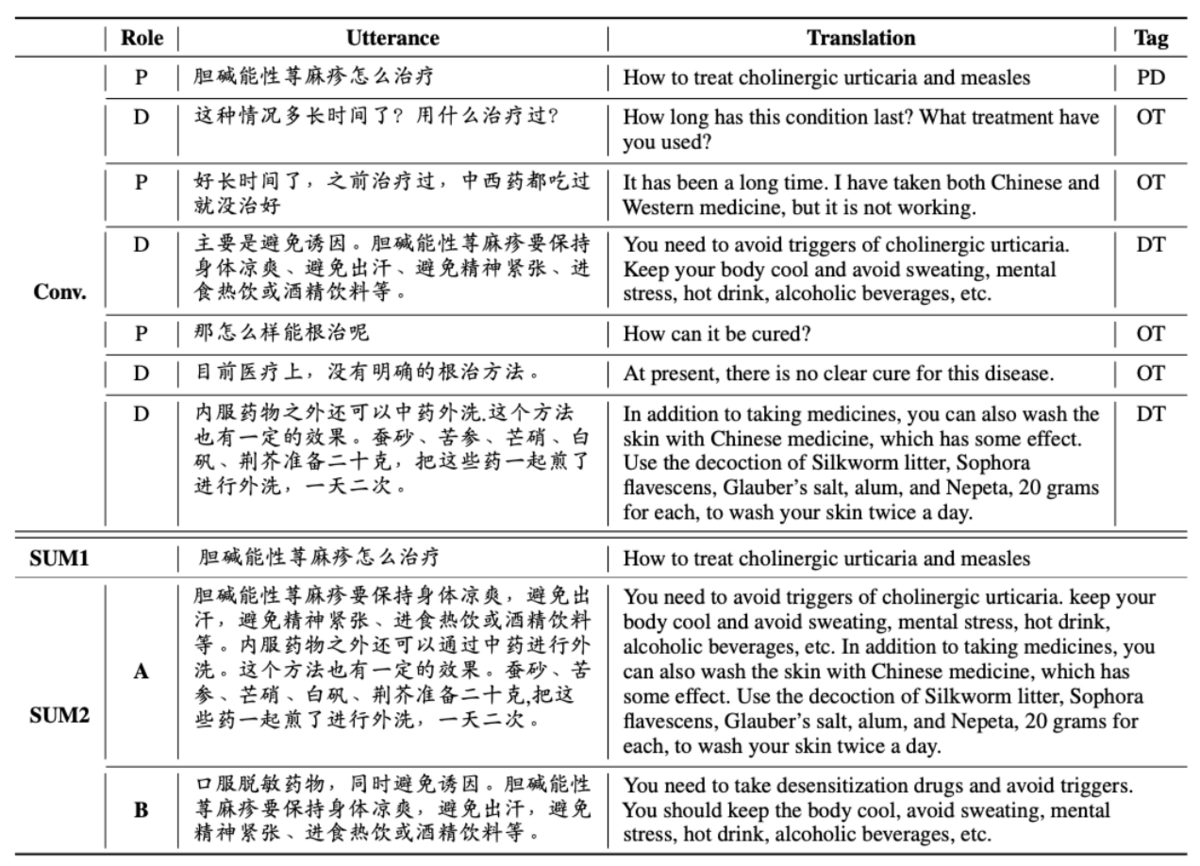
[Song 20]の図を引用し、抽出的対話の例を示します。ここでは、患者の発言のうち特定のトピックに関連するものを抜粋することで対話の要約を作成しています。要約であるSUM1は、対話のうち4番目と7番目の発話をくっつけたものです。
抽象的要約
抽象的要約は、入力文書の主要な概念を含む文書を新しく生成する方法です。機械翻訳などを含むテキスト生成のタスクの一部といえます。 下記に[Chen 21]の図を引用して、抽象的要約の例を示します。要約対象の対話では顔文字や絵文字が多用されていますが、正解として定義される要約文ではそれらは使用されていません。抽出的手法とは異なり、要約文は入力の文書を単に抽出したものではなく、要約手法が生成したものであることがわかります。

その他
情報抽出の手法が与えられた文書の概要を得る方法として使用されていたのでご紹介します。この方法は、事前に要約のためのテンプレートを用意して、情報抽出を使用してその必要箇所を埋めていくことで要約を作成する手法であるとみなせます。
下記の2つの研究では、どちらも医者と患者の対話をまとめるために情報抽出の手法が使用されていました。この手法を適用することで、医師が対話録を読む手間を削減することができます。
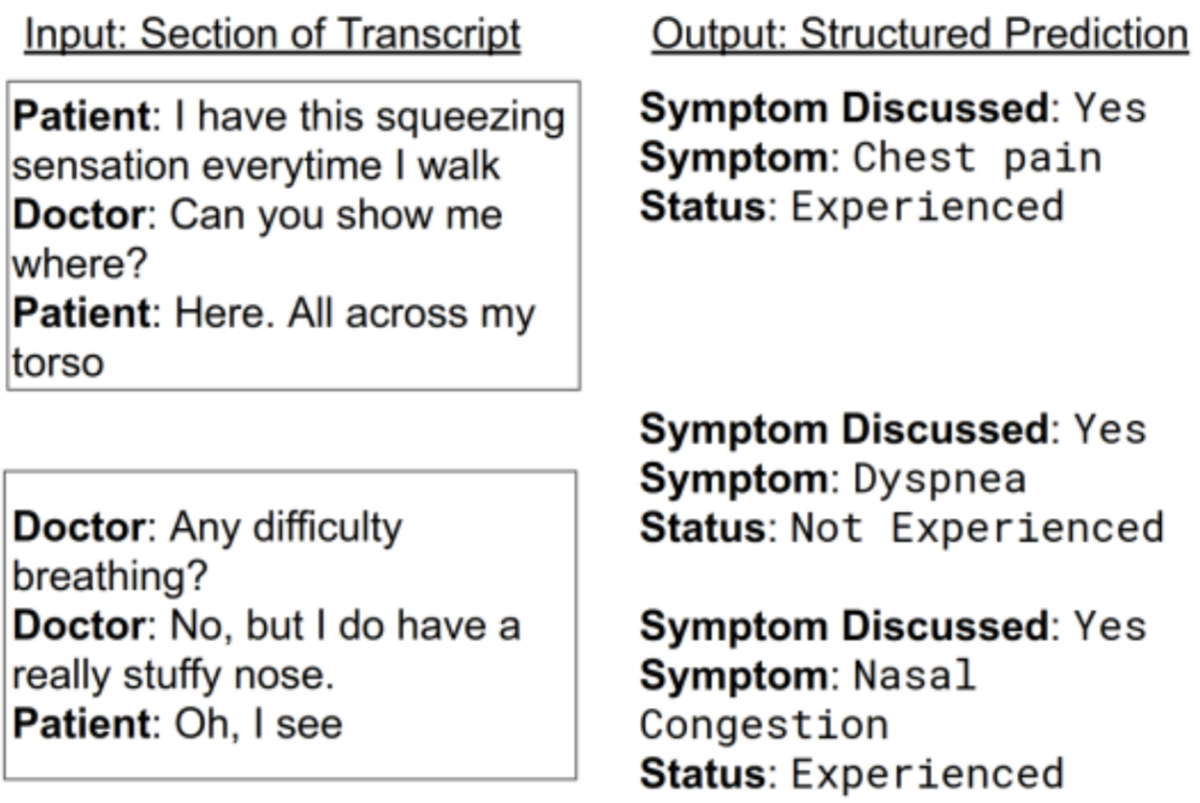
[Kannan 18]では、患者の症状を得るために情報抽出を適用しました。下記に[Kannan 18]の図を引用します。固有表現抽出を用いたシンプルなベースラインでは約20%の症状しか検出できないことが、この研究のモチベーションとなっています。
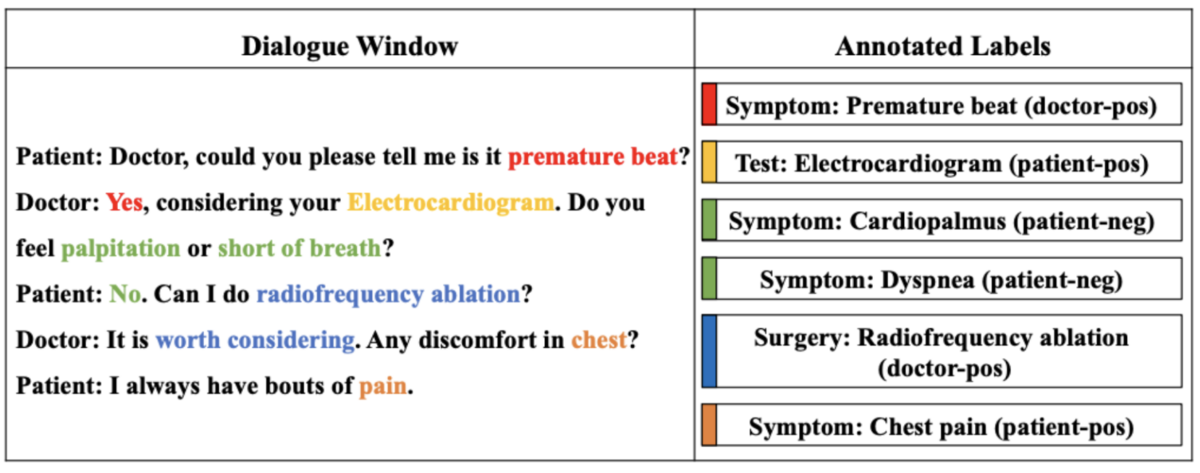
[Zhang 20]では症状だけでなく、検査や手術などの情報も対象にしています。ここでは、LSTMを使ったDeep Matching Modelsと呼ばれる手法を提案しています。手法への入力の単位としてwindowレベルとdialogueレベルがあり、dialogueレベルの場合には適合率が97%以上で情報を獲得できたと報告されています。
近年の研究
以下では、対話要約に関する近年の研究を3つ紹介します。2つは論文の内容であり、1つはRevComm内で評価したものです。
Pegasus
Pegasusは[Zhang 19]によって提案された文書要約モデルです。最近の研究を紹介する文脈で2019年の研究を紹介することに違和感があるかもしれません。ですが、PegasusはGoogleの製品に使用されており、昨今の文書要約モデルの代表のひとつとして選びました。2022年11月のGoogleブログへの投稿では、Google Chatに要約機能が追加され、そこにPegasusを使用していることが報告されています。また、2022年3月のGoogleブログへの投稿では、Google Documentに対する要約作成機能が紹介されており、Pegasusが触れられています。なお、Pegasusを拡張し、より大規模な文書を対象にしたPegasus-Xが2022年に公開されていますが、ここではあくまでもPegasusを対象に説明します。
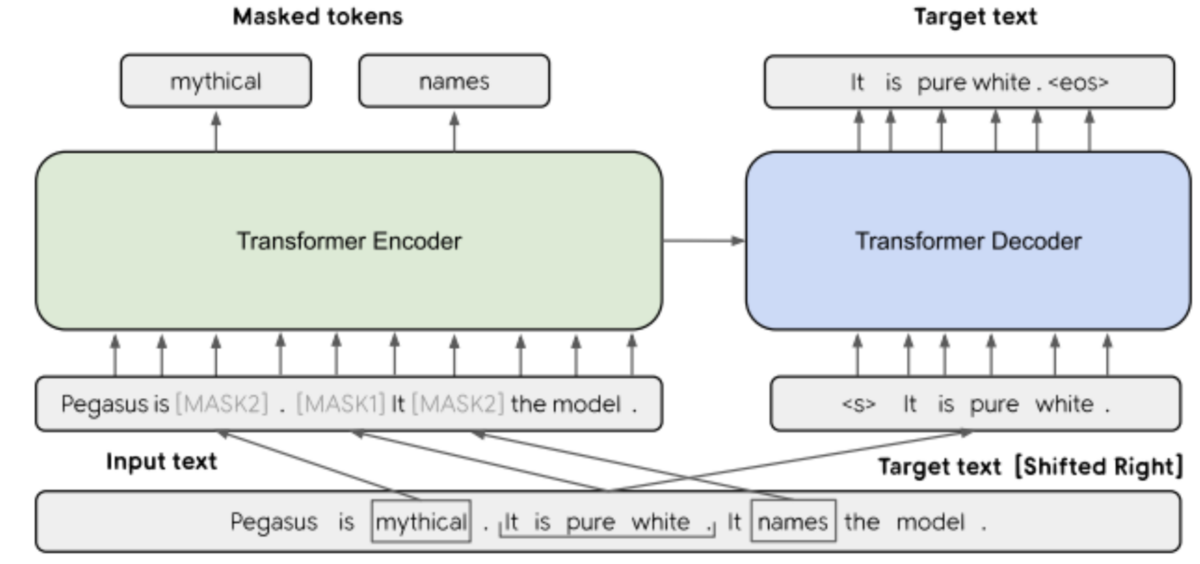
Pegasusは事前学習を工夫しており、その観点ではMasked Language Model (MLM) の発展といえます。MLMは文書の一部の単語を隠し、その隠された部分を推測することで事前学習を行います。この一部を隠した部分をマスクと呼びます。
Pegasusは単語のマスクだけではなく、文のマスクを作成し、それらを推測します。下記にPegasusの概要を示す図を論文から引用します。[MASK1]が文のマスクを示し、[MASK2]が単語のマスクを示します。Pegasusは事前学習において[MASK1]と[MASK2]を推測します。この文のマスクを推定することを、論文中はGap Sentences Generation (GSG) と呼んでいます。
著者らは、文のマスクの選び方について、数種類の方法を比較しています。縦軸は文書要約における性能を示し、ランダムにマスクを選んだ場合を1.0としています。横軸は実験に用いたデータセットです。"MLM Solely” の棒がMLM(単語のマスクのみ)の性能であり、これと他の色を比較すると、文のマスクが性能の向上に寄与していることが分かります。
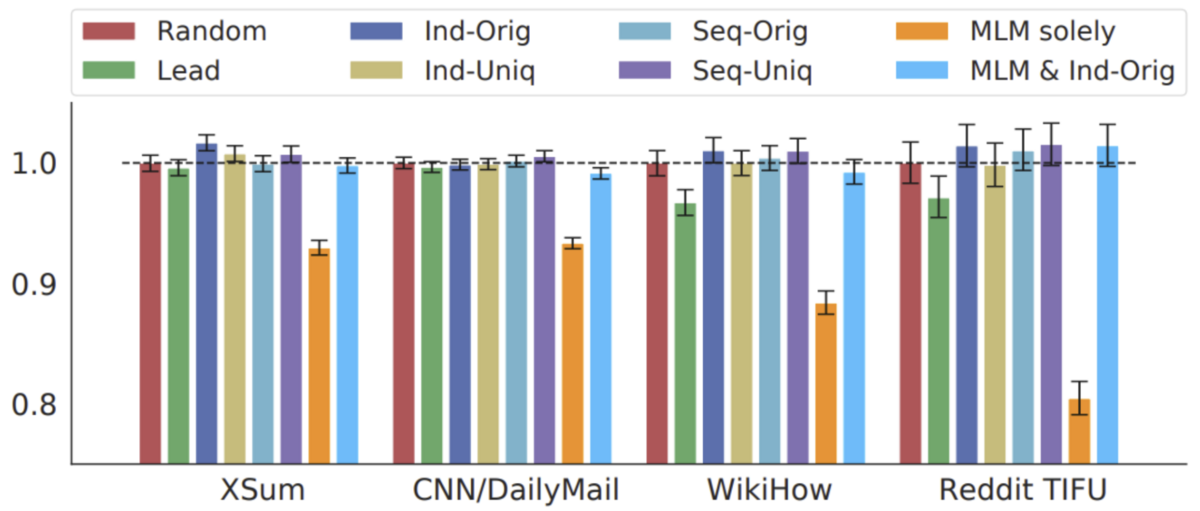
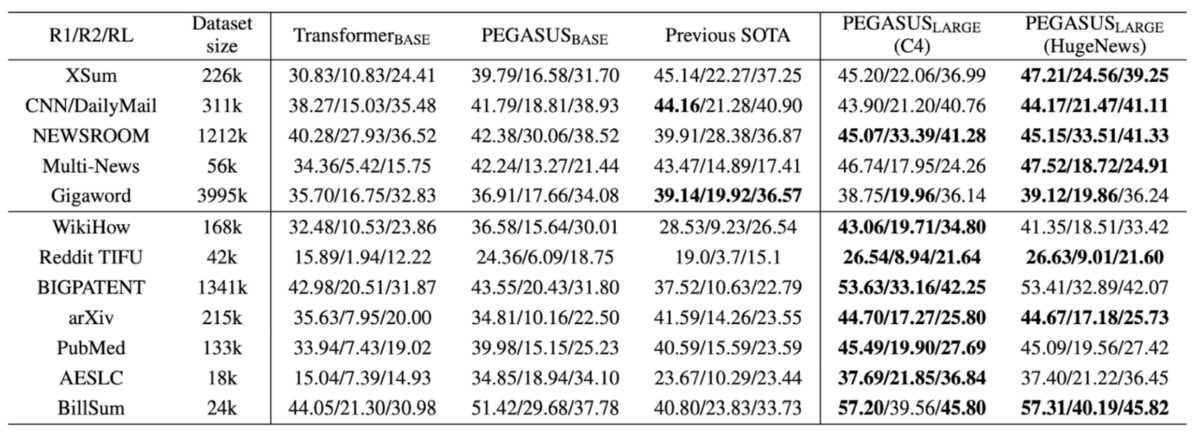
性能評価の実験では、パラメーターのサイズに応じてBASEとLARGEの2種類のモデルが比較されています。BASEは事前学習の対象として単語と文の両方を推測していますが、LARGEでは文のみを推測にしています。
DialogLM
[Zhong 22]は、対話要約モデルDialogLMを提案しています。DialogLMは、この論文の著者がMicrosoftのインターンシップの際に行った研究であり、コードがMicrosoftのGitHubアカウントから提供されています。
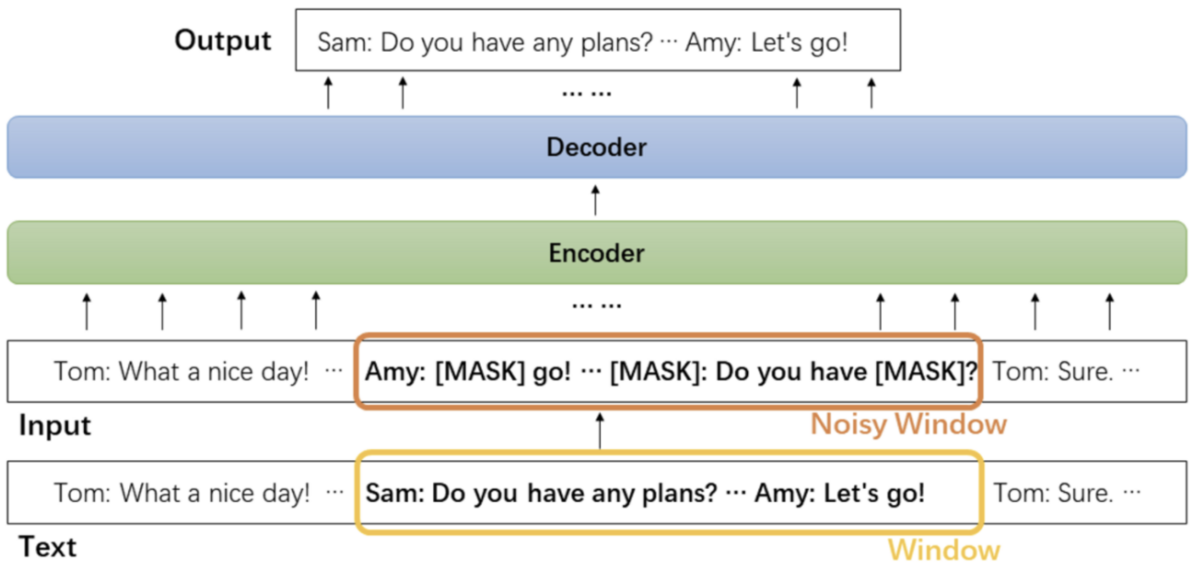
DialogLMでは、先に紹介したPegasusと同様に事前学習が工夫されています。具体的にはWindow-based Denoisingと呼ばれる手法であり、5種類のノイズを対話文に入れて事前学習を行います。ここでの事前学習は、文書の一部の単語を隠し、その隠された部分を推測することです。
下図において、Windowがノイズを入れる前の対話文、Noisy Windowがノイズを入れた対話文です。[MASK]は隠された単語を示しています。このNoisy Windowの部分が本論文で工夫されている点です。
下記にこの論文の図を引用して、この工夫についてもう少し詳しく説明します。この論文では、事前学習において対話に入れるノイズとして、5種類のノイズが試されています。
それぞれのノイズの内容を下記に説明します。
- Speaker Maskでは、話者の部分が隠されます。そして、その隠された話者を言語モデルに推定させます。
- Turn Splittingでは、1つの長い発話が複数の発話に分割されます。そして、最初の発話の話者をそのまま残されますが、分割された2つ目以降の発話の話者を言語モデルに推定させます。
- Turn Merginでは、複数の発話が1つの発話にまとめられます。最初の発話の話者はそのまま残されますが、それ以降の発話の話者は削除されます。
- Text Infillingでは、発話内の単語が隠されます。
- Turn Permutationでは、発話の順序が変更されます。
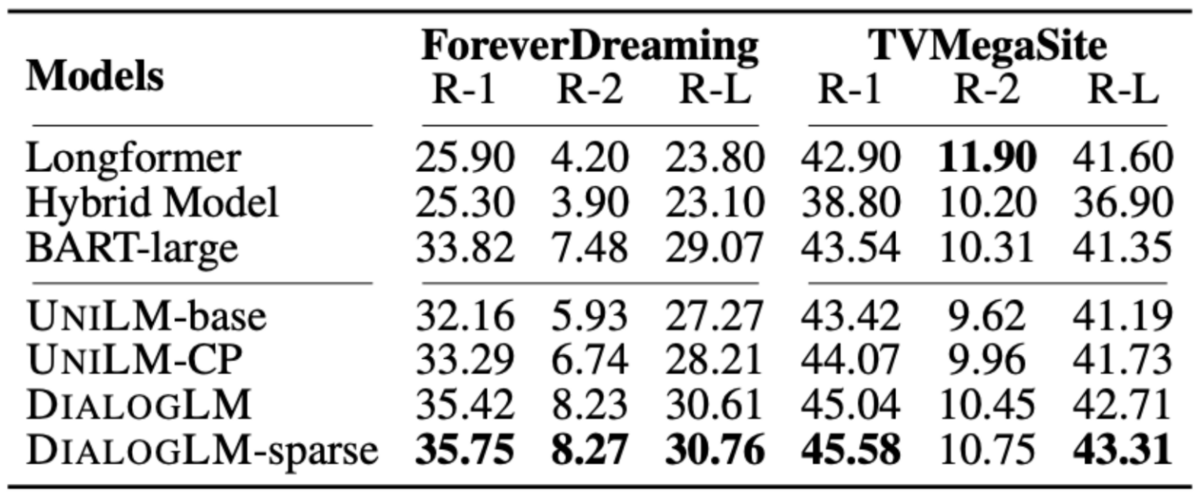
下図は論文から引用した実験結果です。この表で示されているのはForeverDreamingとTVMegaSiteというデータセットを使った場合の結果ですが、他にAMIとICSIというデータセットを使った結果も論文には示されています。ベースラインとして、LongformerやBARTなどが使用されており、提案手法はそれよりも性能が良かったことを示しています。
ChatGPT/GPT3
OpenAIが提供しているChatGPTとGPT3は要約に特化したサービスではありませんが、これを使って要約を行うことができます。そこで、ChatGPT/GPT3を用いた要約の性能について報告します。なお、ChatGPTやGPT3の概要については割愛します。
本記事では、性能を測るためのデータセットとしてSAMSumコーパスを用いました。SAMSumコーパスは、チャットでの短い対話から作成された対話要約のためのデータセットです。このコーパスは広く使用されており、評価結果をさまざまな研究と比較できます。さらに、学習済みの対話要約モデルが多く公開されています。
GPT3の評価では、OpenAIが提供するAPIから「text-davinci-003」モデルを選択しました。ChatGPTの評価では、「gpt-3.5-turbo-0301」モデルを選択しました。
ベースラインとしては、3つの学習済みモデルを使用しました。1つ目はphilschmid/bart-large-cnn-samsum(以下、BART-large)で、これはBARTをCNN Daily Mailコーパスと SAMSumコーパスの2つの要約データセットでファインチューニングしたものです。2つ目はphilschmid/flan-t5-base-samsum(以下、Flan-T5-base)で、これはflan-t5-baseをSAMSumコーパスでファインチューニングしたものです。最後はjaynlp/t5-large-samsum(T5-large)で、最近の対話要約に関する論文の成果物のひとつです。
さらに、UL2とPegasusの2つのモデルのスコアを参照しました。 UL2は2022年後半に提案されたモデルであり、そのモデルがSAMSumコーパスで最先端のスコアを達成したと主張されています。 Pegasus は、Googleが提供しているサービスの要約機能で使用されているモデルであり、最も洗練された要約モデルのひとつです。
評価指標としてBLEUとROUGEの2種類を使用しました。結果を下記の表に示します。
| モデル | BLEU | ROUGE1 | ROUGE2 | ROUGEL |
|---|---|---|---|---|
| ChatGPT | 0.093 | 0.406 | 0.165 | 0.318 |
| GPT3 | 0.111 | 0.423 | 0.171 | 0.340 |
| BART-large | 0.123 | 0.403 | 0.203 | 0.312 |
| Flan-T5-large | 0.212 | 0.516 | 0.274 | 0.431 |
| T5-large | 0.200 | 0.506 | 0.262 | 0.418 |
| UL2 | - | - | 0.296 | - |
| Pegasus | - | 0.523 | 0.283 | 0.4783 |
GPT3はChatGPTよりも高いスコアを獲得しました。そして、ファインチューニングされたモデル (BART-large, Flan-T5-base, T5-large) はGPT3よりも優れていることがわかります。この結果は、2023年2月に発表された論文で報告されている内容と一致します。ただし、この論文では実験の際に40GB程度の大きなモデルを使用しているため、小さなモデル(例えば、T5-largeは3GB程度です)がGPT3およびChatGPTの性能を上回るという事実は、この実験で初めて明らかになりました。
Flan-T5-largeはGPT3/ChatGPTと比較して小さなモデルですが、GPT3/ChatGPTよりも高いスコアを獲得しました。この事実は、非常に大規模なモデルを使用せずに、高精度な要約モデルを開発できることを示唆しています。ただし、開発にChatGPTのような非常に大きなモデルが不要であるというわけではありません。ChatGPTを使用することでデータ拡張や教師データの作成などを行い、開発をスピードアップすることが可能だと思われます。
BART-largeは、ファインチューニングされたモデルの中では最低の性能でした。 BARTは要約タスクを含むテキスト生成タスクのベースラインとして頻繁に使用されており、一般に性能が低いわけではありません。
GPT3とChatGPTのスコアが低かった原因を分析するために、スコアが低かった要約結果の中身を確認しました。その結果、スコアが低かったにもかかわらず、対話の重要な部分はしっかりまとまっていることが確認されました。ただし、その表現は正解として定義された要約文を言い換えたものであり、単語でのマッチングをもとに評価を行うやBLEUやROUGEでは不正解と見なされていました。これはやBLEUやROUGEの弱点であり、この問題に対処するために近年いくつかのスコアが提案されています。詳しくは前編記事をご覧ください。
まとめ
本記事では、対話要約の最近の研究としてPegasus、 DialogLM、そしてRevComm内でGPT3/ChatGPTを評価した結果を紹介しました。
GPT3/ChatGPTの評価では、SAMSumコーパスを使用してGPT3とChatGPTの対話要約性能を評価しました。
GPT3はChatGPTよりも高いBLEU/ROUGEスコアを獲得しましたが、BARTやFlan-T5などをSAMSumコーパスでファインチューニングしたモデルはGPT3よりもさらに高いスコアを獲得しました。しかし、GPT3/ChatGPTによる要約結果は必ずしも悪いものではなく、むしろBLEUやROUGEといったスコアに改良が必要であることが示唆されました。
引用
- [Chen 21] Chen, Y., Liu, Y., and Zhang, Y.: DialogSum Challenge: Summarizing Real-Life Scenario Dialogues, in Proceedings of the 14th International Conference on Natural Language Generation, pp. 308–313, Aberdeen, Scotland, UK (2021), Association for Computational Linguistics
- [Kannan 18] Kannan, A., Chen, K., Jaunzeikare, D., and Ra- jkomar, A. R.: Semi-supervised learning for information extraction from dialogue (2018)
- [Song 20] Song, Y., Tian, Y., Wang, N., and Xia, F.: Summarizing Medical Conversations via Identifying Important Utterances, in Proceedings of the 28th International Conference on Computational Linguistics, pp. 717–729, Barcelona, Spain (Online) (2020), International Committee on Computational Linguistics
- [Zhang 20] Zhang, Y., Jiang, Z., Zhang, T., Liu, S., Cao, J., Liu, K., Liu, S., and Zhao, J.: MIE: A Medical Information Extractor towards Medical Dialogues, in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 6460–6469, Online (2020), Association for Computational Linguistics
- [Zhang 19] Zhang, J., Zhao, Y., Saleh, M., and Liu, P. J.: PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization (2019)
- [Zhong 22] Zhong, M., Liu, Y., Xu, Y., Zhu, C., and Zeng, M.: Dialoglm: Pre-trained model for long dialogue understanding and summarization, in Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 36, pp. 11765–11773 (2022)