本記事の著者はResearch Engineerの大野です。最近は、ホロウナイトというゲームをやっていましたが、もう少しでクリアというところで敵が倒せず諦めました。
はじめに
RevCommは電話営業や顧客応対の通話を支援するAI搭載型のIP電話「MiiTel」を提供しています。 この製品は、通話の文字起こしを保存する機能を備えており、RevCommは数千時間の対話データに接しています。
この対話データに対する支援の1つとして対話要約が考えられます。対話要約とは、入力された対話から、その主要な概念を含むより短い文書(要約)を自動的に作成することです。 ユーザは、要約を作成する手間が省けたり、あるいは要約を読むことで対話の概要をより早く理解できるなどの利点があります。
これから前編と後編の2回に分けて、対話要約に関する記事を書きます。今回の記事では、はじめにいくつかの対話要約のデータセットをご紹介します。 対話要約は、メール・チャット・エージェントと顧客間の対話など、複数のドメインで使用されます。そして、ドメインによって課題やゴールが異なります。そこでデータセットをいくつかご紹介することで、各ドメインの抱える課題やゴールを概観していきます。
また、本記事では要約システムの評価指標についてもご紹介します。長らく単語のオーバーラップに基づく指標が使用されていましたが、他の内容に基づく評価指標が最近になって提案されています。 評価指標を概観することは、要約システムを構築する際の課題を考える良い材料になると考えています。
データセット
[Jia 22] は対話要約を2つに分類しました。1つはオープンドメイン対話要約で、もう1つはタスク指向対話要約です。下記に[Jia 22]の図を引用します。
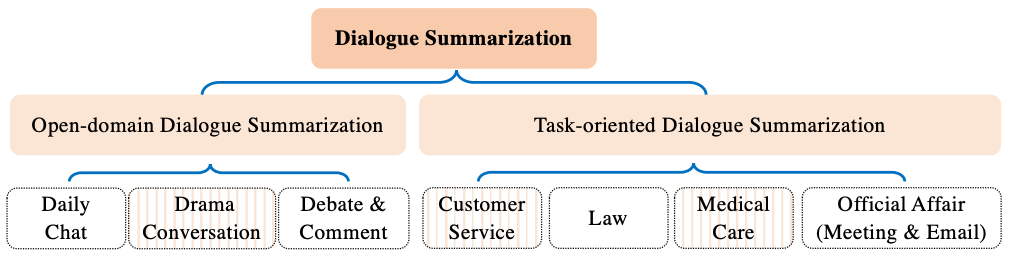
オープンドメイン対話要約は、日常生活やドラマにおける対話、あるいはオンラインフォーラムを対象にした要約です。物語の大筋を獲得したり、与えられたテーマに対する意見をまとめることに焦点を当てます。この記事では、オープンドメイン対話要約のデータセットとして、「チャット」「日常会話」「TV番組・インタビュー」の3つのカテゴリを取り上げます。
タスク指向の対話要約は、主に顧客とサービスプロバイダに所属するエージェントとの間の会話を対象にします。顧客は特定の課題を持っており、それを解消するためにエージェントと対話をします。この記事では、タスク指向の対話要約のデータセットとして、「会議」「メール」「医療」「カスタマーサービス」の4つのカテゴリを取り上げます。
オープンドメイン対話要約
チャット
[Gliwa 19]は対話要約のためのデータセットであるSAMSum(Samsung Abstractive Messenger Summarization)を作成しました。データセットの名前が示すように、著者はSamsungに所属しています。
データセットはオンラインチャットと要約のペアを約1万6000件含んでいます。[Zhao 21]によると、ターン数は平均して9.9回です。オンラインチャットの性質上、データセットが絵文字・顔文字あるいは略語を含んでいます。下記に[Chen 21]の図を引用して、このデータセットに含まれる対話の例を示します。

日常会話
[Chen 21]は対話要約のためのデータセットDialogSumを作成しました。このデータセットは、学校・ビジネス・レジャーなどの、日常生活における様々なトピックに関連した対話を約1万3000件含みます。
DialogSumは主に下記の3つのデータセットから作成されました。これらは対話要約のためのデータセットではありません。例えば、[Sun 19]のDREAMはdialogue understandingというタスクのデータセットです。
- [Li 17]のDailydialog
- [Sun 19]のDREAM
- [Cui 20]のMuTual
下記に[Chen 21]の図を引用して、DialogSumに含まれる対話の例を示します。これはビジネス上の対話です。

[Mehnaz 21]は、英語とヒンディー語混じりの対話要約のデータセットである、GupShupを作成しました。このデータセットは、[Gliwa 19]によって作成されたSAMSumをもとに作成されました。
このデータセットはコードスイッチングと呼ばれる、会話中に話し手が異なる言語を切り替えて話す現象に着目しています。論文には、「会話エージェントやチャットプラットフォームの普及に伴い、世界中の多くの多言語コミュニティにおいて、コードスイッチングは文字による会話に不可欠なものとなっています」と書かれています。
下記に[Mehnaz 21]の図を引用します。青い部分が英語で、紫の部分がヒンディー語です。この例では英語での要約だけが示されていますが、データセットは英語とヒンディー語混じりの要約も含みます。

TV番組・インタビュー
[Chen 22]はTV番組の対話要約データセットであるSummScreenを作成しました。このデータセットは、次の2つのステップにより作成されました。まず、TVMegaSiteとForeverDreamingから、TV番組のトランスクリプトを獲得します。次に、そのトランスクリプトの要約として、WikipediaとTVmazeから番組概要を獲得しました。
下記に[Chen 22]の図を引用し、SummScreenに含まれる対話の例を示します。青い枠にあるSheldonとLeonardの会話は、物語の大筋に関連が薄いため要約文には出てきません。

[Zhu 21]は米国公共ラジオ放送(National Public Radio; NPR)とCNNで行われたインタビューから、MediaSumを作成しました。ここでは、一般に公開されているインタビューの原稿を対話文とし、NPRとCNNに掲載されたインタビューの説明を要約文としました。
タスク指向の対話要約
会議
[Carletta 05]は 会議のマルチモーダルなデータセットであるAMI meeting corpusを作成しました。架空のデザインチームが、リモコンのデザインを話し合うために行ったミーティングが、このデータセットに含まれます。また、視線の方向やホワイトボードの情報などの対話以外の情報も含まれています。このデータセットを日本語に翻訳したデータセットも存在します。
[Zhong 21]はQMSumを提案しました。これは、クエリに基づく要約タスクのためのデータセットであり、232件の会議に関連する1808件のクエリと要約の組から構成されています。[Janin 03]によるICSI Meeting Corpusと[Carletta 05]によるAMI meeting corpusと議会のミーティングから作成されました。
クエリとは、システムが出力する要約に対する制限です。クエリの例として「Summarize the discussion about remote control style and use cases.」や「Summarize Project Manager's opinion towards remote control style and use cases.」が挙げられます。
オンラインチャットなどのこれまでご紹介したデータセットと比較して、会議はその文量が多く、また多様なトピックを含みます。そのため、会議から短い要約を作成することは難しいことと、参加者によって知りたい内容が異なることに[Zhong 21]は着目しました。その結果、与えられたクエリに応じて要約を作成する対話要約システムのためのデータセットを作成しました。
下記に[Zhong 21]の図を引用し、クエリに基づく要約の例を示します。3つのクエリが入力され、各々に対して対話要約システムが要約を作成します。

メール
[Zhang 21a] は、2549件の電子メールスレッドからなるデータセットであるEmailSumを作成しました。各々のスレッドは3件から10件のメールを含みます。また、30単語以下の短い要約と100単語以下の長い要約が、各スレッドに付与されています。
このデータセットは下記の3つのメールのデータセットから作成されました。これらにはスレッド構成が整理されていませんでした。そのため、スレッド構成を整理して、要約を作成することが[Zhang 21a]の貢献と言えます。
- [Klimt 04]が作成したEnron
- [Craswell 06]が作成したW3C
- Avocado Research Email Collection
下記に[Zhang 21a]の図を引用し、短い要約と長い要約の例を示します。

医療
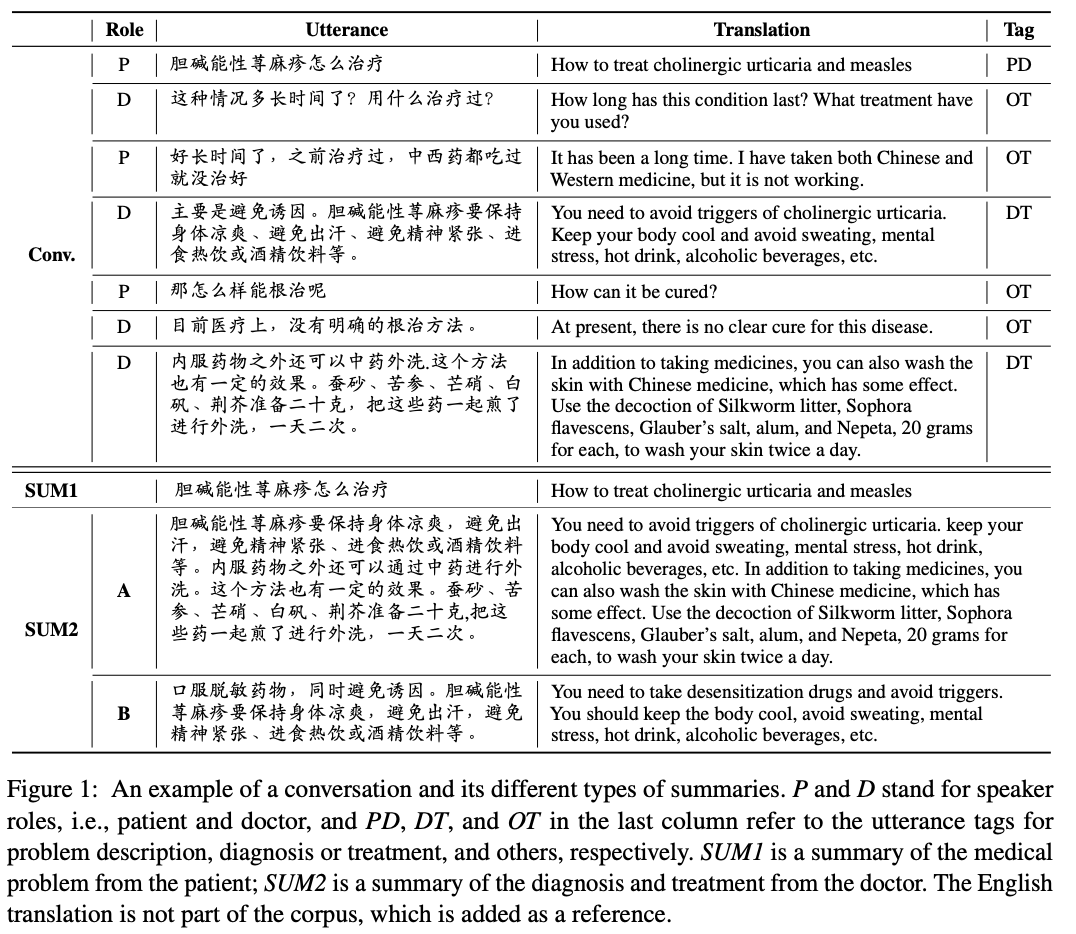
[Song 20]は公開フォーラムで医者と対話できるプラットフォームであるChunyu-Doctorから対話要約のためのデータセットを作成しました。フォーラム上の対話に対話要約を適用する目的を、医師の手間を削減するためとしています。
[Song 20]の図を引用し、対話の例を示します。ここでは、患者の発言のうち特定のトピックに関連するものを抜粋しています。
カスタマーサービス
カスタマーサービスは、企業に所属するエージェントが顧客に対して何らかのサービスを行うことです。対話要約を適用する理由の1つには、エージェントの負担軽減があります。[Liu 19]は、滴滴出行(DiDi)で働く30万のエージェントと顧客の対話に対して、対話要約を適用した論文です。この論文のモチベーションの項では「要約の作成にはエージェントの時間の約25%が費やされています。DiDiには数千人のエージェントがいます。そのため、要約の自動生成は膨大な人的資源を節約することができます。」と書かれています。
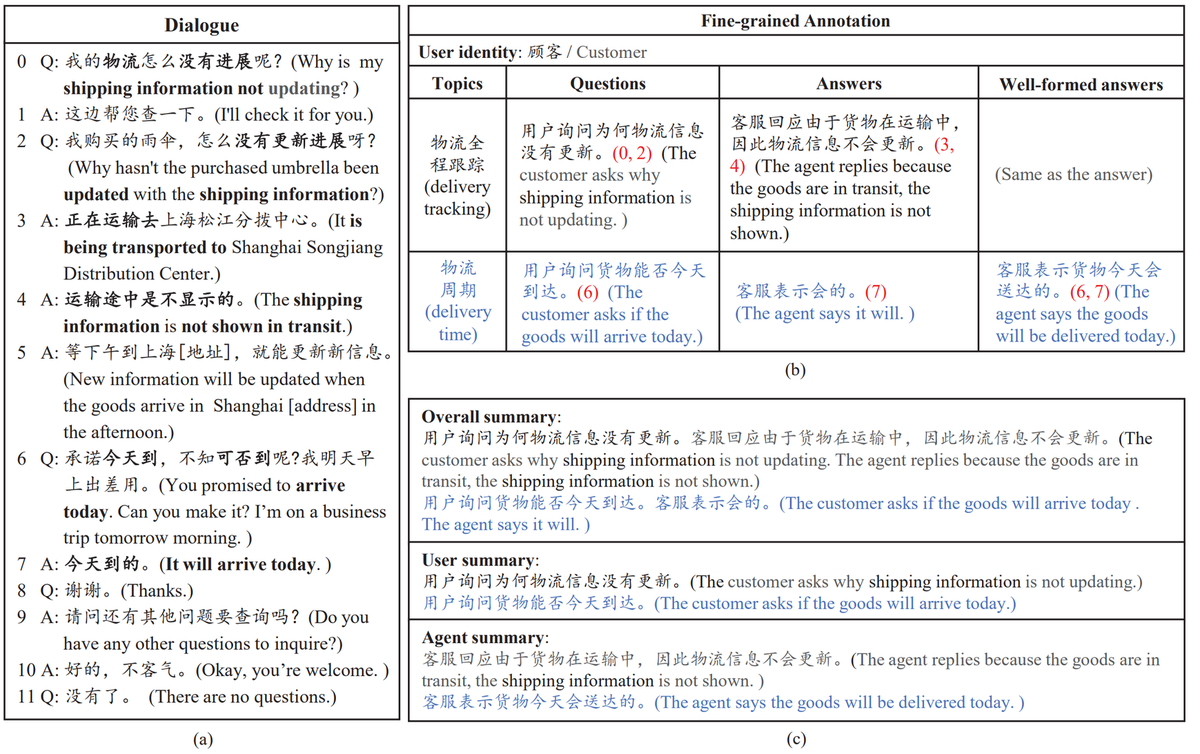
[Lin 21]は中国語で書かれた対話要約のデータセットであるCSDS(Customer Service domain Dialogue Summarization)を作成しました。これは[Chen 20]が作成した対話データセットJDDCに要約を付け加えることで作成されています。JDDCは、中国のe-コマース最大手である京東商城(JD)のスタッフと顧客間のプリセールスとアフターセールスの対話から構成されています。
下記に[Lin 21]の図を引用します。注文した商品の配送に関して、スタッフと顧客が話し合っており、これに対して3種類の要約が付与されています。
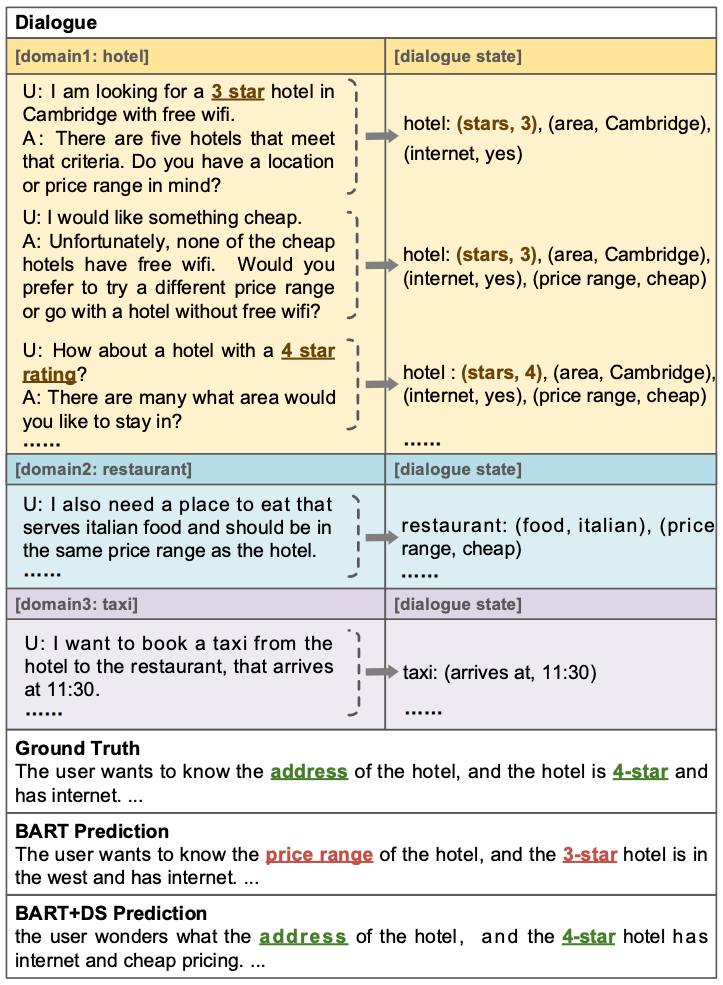
[Zhao 21]は、5つのドメイン(レストラン、ホテル、アトラクション、タクシー、電車)における、約1万の対話とその要約を含んだデータセットTODSumを作成しました。この論文の著者の所属は3つに別れており、北京郵電大学と美団(Meituan)と中国移動(China Mobile)です。美団はe-コマースプラットフォームである美団と、口コミサイトである大衆点評を運営しています。中国移動は世界最大の携帯電話事業者です。
下記に[Zhao 21]の図を引用し、TODSumに含まれる対話の例を示します。
阿里巴巴(Alibaba)に所属する[Zou 21a]は淘寶(Taobao)で行われた顧客とエージェントのチャットログ109万件を使用して、対話要約に取り組みました。この研究で使用された実装とデータセットが公開されています。この論文の著者は、[Zou 21b]において、阿里巴巴のコールセンターで行われた顧客とエージェントの対話に対して、対話要約を適用したことを報告しています。ただし、こちらはデータセットが公開されていません。
評価手法
要約の手法を評価するための評価指標をいくつか紹介します。これまでは、正解と定義された要約文とシステムが出力した要約文の類似度を計算し、その類似度が高ければ良い要約文と判断していました。近年になって、質問応答システムを使用するなどの、いくつかの評価指標が提案されています。ここでは数式なしで説明しようと試みており、いくつかの評価指標には数式を示していません。
ROUGE
ROUGEは最も広く使われる評価指標の1つで、この指標を提案した[Liu 04]の引用件数は9000件を超えています。 ROUGEは2つの文書に共通する単語数に着目して、2つの文書の類似度を計算します。いくつかの派生があり、ROUGE-1はuni-gram(単語)を使用し、ROUGE-2はbi-gram(連続する2単語)を使用します。Huggingface社のライブラリであるevaluateに実装があります。
BLEU
[Papineni 02]によるBLEUは共通する単語n-gramの数に着目し、類似度を計算します。nはパラメタであり、1から4がよく使用されます。言い換えれば、単語だけでなく、連続する2単語・3単語・4単語に着目します。また、システムが出力した要約文が、正解と定義された要約文よりも短い時にペナルティを与えるように工夫されています。Huggingface社のライブラリであるevaluateに実装があります。
下記に計算式を示します。ここでは、システムが出力した要約文の数と、正解と定義された要約文の数が共に1である時の計算式を示しています。BPはシステムが出力した要約文が正解と定義された要約文よりも短い時のペナルティです。または与えられた文の単語n-gramを返す関数です。pnは2つの文に存在する単語n-gramのうち、共通する単語n-gramの割合を表します。N=4がよく使用され、1-gramから4-gramに基づきBLEUが計算されます。
chrF
[Popovi ́c 15]によるchrFは、上記のROUGE・Bleuと異なり、単語ではなく文字n-gramに着目します。はじめに文字n-gramの集合を、正解と定義された要約文と、システムが出力した要約文のそれぞれから獲得します。次にそれらの 適合率と再現率を求め、最後にF値を計算します。 Huggingface社のライブラリであるevaluateに実装があります。n=6が論文で使用されており、また実装でもデフォルト値はn=6となっています。
BERTScore
これまでにご紹介した指標では、2つの単語を比較する際に完全一致するかを確認しており、同義語や類義語を扱えませんでした。[Zhang* 20a]によるBERTScoreは言語モデルを使用してこの問題に取り組みます。
はじめに言語モデルを用いて、正解と定義された要約文の各トークンをベクトルに変換したものをxとします。次に、システムが出力した要約文の各トークンをベクトルに変換したものをyとします(論文中ではx^でしたが、今回記事を書いた時に読みにくいと感じたのでyに変更しています)。
下記に計算式を示します。 再現率と適合率を計算した後に、その調和平均を求めます。
数式よりも図を使った説明の方が直感的で分かりやすいかもしれません。下記に[Zhang* 20a]の図を引用し、BERTScoreの概要を示します。Contextual Embeddingの部分に置かれたキャラクタはセサミストリートに登場するBertです。Importance Weightingの部分は上の手順では説明を省略した部分です。基本的にはBERTScoreは各トークンに重みを付けることはしませんが、idfなどを使用して重み付けすることもできます。
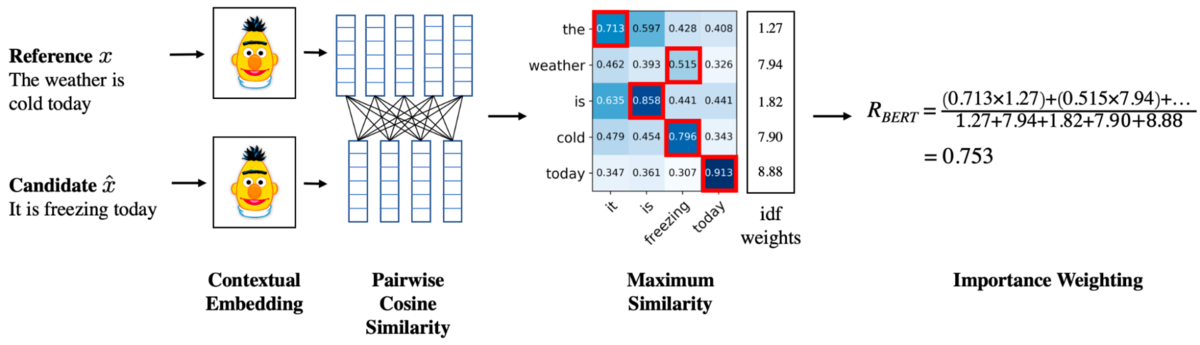
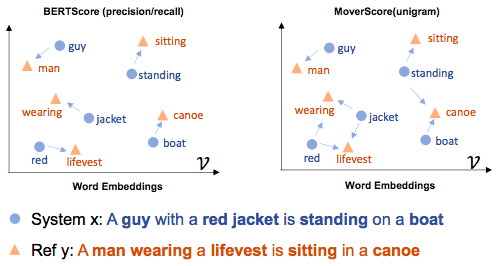
また、[Zhao 19]の図を示します。こちらの方がBERTScoreの概要が理解しやすいかもしれません。青色の「System」がシステムが出力した要約文であり、オレンジ色の「Ref」が正解と定義された要約文です。BERTScoreでは、guyとmanあるいはboatとcanoeなどの類似した語を扱うことができ、単純に共通な単語数を数えるよりもより正確な評価が期待できます。
FEQA
[Durmus 20]のFEQAは質問応答システムを利用する指標であり、factual consistencyという観点で要約を評価します。言い換えれば、システムが生成した要約文の内容が、要約前の文書の内容にどれくらい近いかを評価しています。下記に、[Durmus 20]の図を引用し、factual consistencyが欠けた要約の例を示します。ここでは、要約前の文書に「born」と書かれていますが、要約文は「died」と書きました。この単語の違いは内容に大きく影響を与えます。

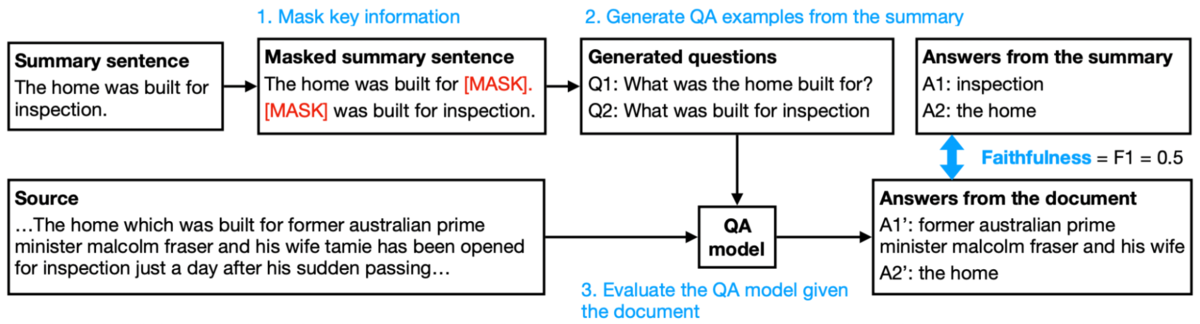
FEQAは3つのステップから構成されています。はじめにシステムが出力した要約文のあるフレーズを[MASK]に置換します。次に[MASK]が答えになるような質問を生成します。最後に質問と要約前の文書を質問応答システムに入力し、置換前のフレーズが答えとして出力されるか確認します。
[Durmus 20]の図を下記に引用し、この指標の計算例を示します。「The home was built for inspection.」という文がシステムが生成した要約文です。ここから、「Q1: What was the home built for?」「Q2: What was built for inspection?」という 2つの質問が作成されました。これらの質問に対する質問応答システムの出力は「A1’: former australian prime minister malcolm fraser and his wife」「A2’: the home」であり、片方は期待されたものと異なります。
各ステップの実装についても簡単に紹介します。はじめのステップでは固有表現抽出や句構造解析器(constituency parser)を使用して[MASK]に置換する箇所を探します。次のステップでは、QA2Dデータセットで訓練したseq2seqモデルが使用されます。最後のステップでは、SQuAD (Stanford Question Answering Dataset)でファインチューニングしたBERTを使用します。実装は公開されています。
FactSumm
FactSummはトリプル抽出を利用した指標であり、factual consistencyを評価します。トリプルとは、2つのオブジェクトとそれらの関係の3つから構成されたデータの表現方法の一種です。FactSummは、要約文と要約前の文書の各々にトリプル抽出を適用して、その結果を比較することで評価を行います。FactSummは論文として公開されておらず、GitHubで文書と実装が公開されています。
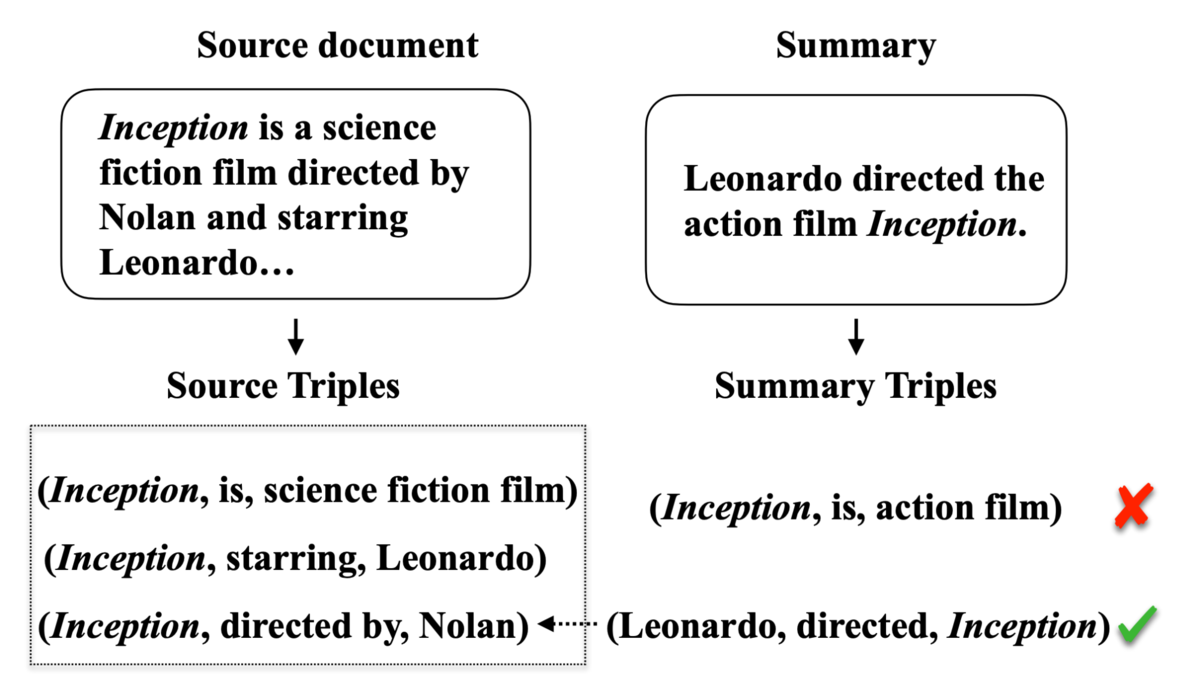
下記にFactSummのGitHubレポジトリから図を引用し、その処理の概要を示します。要約前の文書からは、(Inception, is, science fiction film)というトリプルが抽出され、要約文からは(Inception, is, action film)というトリプルが抽出されました。この2つは異なるので、要約文はfactual consistencyが欠けていると言えます。
まとめ
この記事では下記のことを行いました。後編では、最近の対話要約手法について書く予定です。
- オープンドメイン対話要約のデータセットとして、「チャット」「日常会話」「TV番組・インタビュー」の3つのカテゴリを取り上げました。
- タスク指向の対話要約のデータセットとして、「会議」「メール」「医療」「カスタマーサービス」の4つのカテゴリを取り上げました。
- ROUGE・Bleu・chrF・BERTScore・FEQA・FactSummを取り上げました。FEQA・FactSummは、factual consistencyを評価する指標であり、これまで用いられてきた単語のオーバーラップに基づく指標とは大きく異なります。
参考文献
- [Carletta 05] Carletta, J., Ashby, S., Bourban, S., Flynn, M., Guillemot, M., Hain, T., Kadlec, J., Karaiskos, V., Kraaij, W., Kronenthal, M., Lathoud, G., Lincoln, M., Lisowska, A., McCowan, I., Post, W., Reidsma, D., and Wellner, P.: The AMI Meeting Corpus: A PreAnnouncement, in Proceedings of the Second International Conference on Machine Learning for Multimodal Interaction, MLMI’05, pp. 28–39, Berlin, Heidelberg (2005), Springer-Verlag
- [Chen 20] Chen, M., Liu, R., Shen, L., Yuan, S., Zhou, J., Wu, Y., He, X., and Zhou, B.: The JDDC Corpus: A LargeScale Multi-Turn Chinese Dialogue Dataset for E-commerce Customer Service, in Proceedings of the Twelfth Language Resources and Evaluation Conference, pp. 459–466, Marseille, France (2020), European Language Resources Association
- [Chen 21] Chen, Y., Liu, Y., and Zhang, Y.: DialogSum Challenge: Summarizing Real-Life Scenario Dialogues, in Proceedings of the 14th International Conference on Natural Language Generation, pp. 308–313, Aberdeen, Scotland, UK (2021), Association for Computational Linguistics
- [Chen 22] Chen, M., Chu, Z., Wiseman, S., and Gimpel, K.: SummScreen: A Dataset for Abstractive Screenplay Summarization, in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 8602–8615, Dublin, Ireland (2022), Association for Computational Linguistics
- [Craswell06] Craswell, N., Vries, A., and Soboroff, I.: Overview of the TREC-2005 Enterprise Track, Text Retrieval Conference (TREC), , USA (2006)
- [Cui 20] Cui, L., Wu, Y., Liu, S., Zhang, Y., and Zhou, M.: MuTual: A Dataset for Multi-Turn Dialogue Reasoning, in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 1406–1416, Online (2020), Association for Computational Linguistics
- [Durmus 20] Durmus, E., He, H., and Diab, M.: FEQA: A Question Answering Evaluation Framework for Faithfulness Assessment in Abstractive Summarization, in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 5055–5070, Online (2020), Association for Computational Linguistics
- [Feigenblat 21] Feigenblat, G., Gunasekara, C., Sznajder, B., Joshi, S., Konopnicki, D., and Aharonov, R.: TWEETSUMM A Dialog Summarization Dataset for Customer Service, in Findings of the Association for Computational Linguistics: EMNLP 2021, pp. 245–260, Punta Cana, Dominican Republic (2021), Association for Computational Linguistics
- [Gliwa 19] Gliwa, B., Mochol, I., Biesek, M., and Wawer, A.: SAMSum Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization, in Proceedings of the 2nd Workshop on New Frontiers in Summarization, pp. 70–79, Hong Kong, China (2019), Association for Computational Linguistics
- [Janin 03] Janin, A., Baron, D., Edwards, J., Ellis, D., Gelbart, D., Morgan, N., Peskin, B., Pfau, T., Shriberg, E., Stolcke, A., and Wooters, C.: The ICSI Meeting Corpus, in 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, 2003. Proceedings. (ICASSP ’03)., Vol. 1, pp. I–I (2003)
- [Jia 22] Jia, Q., Ren, S., Liu, Y., and Zhu, K. Q.: Taxonomy of Abstractive Dialogue Summarization: Scenarios, Approaches and Future Directions (2022)
- [Klimt 04] Klimt, B. and Yang, Y.: The Enron Corpus: A New Dataset for Email Classification Research, in Proceedings of the 15th European Conference on Machine Learning, ECML’04, pp. 217–226, Berlin, Heidelberg (2004), SpringerVerlag
- [Li 17] Li, Y., Su, H., Shen, X., Li, W., Cao, Z., and Niu, S.: DailyDialog: A Manually Labelled Multi-turn Dialogue Dataset, in Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pp. 986–995, Taipei, Taiwan (2017), Asian Federation of Natural Language Processing
- [Lin 04] Lin, C.-Y.: ROUGE: A Package for Automatic Evaluation of Summaries, in Text Summarization Branches Out, pp. 74–81, Barcelona, Spain (2004), Association for Computational Linguistics
- [Lin 21] Lin, H., Ma, L., Zhu, J., Xiang, L., Zhou, Y., Zhang, J., and Zong, C.: CSDS: A Fine-Grained Chinese Dataset for Customer Service Dialogue Summarization, in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 4436–4451, Online and Punta Cana, Dominican Republic (2021), Association for Computational Linguistics
- [Liu 19] Liu, C., Wang, P., Xu, J., Li, Z., and Ye, J.: Automatic dialogue summary generation for customer service, in Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 1957– 1965 (2019)
- [Mehnaz 21] Mehnaz, L., Mahata, D., Gosangi, R., Gunturi, U. S., Jain, R., Gupta, G., Kumar, A., Lee, I. G., Acharya, A., and Shah, R. R.: GupShup: Summarizing Open-Domain Code-Switched Conversations, in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 6177–6192, Online and Punta Cana, Dominican Republic (2021), Association for Computational Linguistics
- [Papineni 02] Papineni, K., Roukos, S., Ward, T., and Zhu, W.-J.: Bleu: a Method for Automatic Evaluation of Machine Translation, in Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pp. 311–318, Philadelphia, Pennsylvania, USA (2002), Association for Computational Linguistics
- [Popovi ́c 15] Popovi ́c, M.: chrF: character n-gram F-score for automatic MT evaluation, in Proceedings of the Tenth Workshop on Statistical Machine Translation, pp. 392–395, Lisbon, Portugal (2015), Association for Computational Linguistics
- [Song 20] Song, Y., Tian, Y., Wang, N., and Xia, F.: Summarizing Medical Conversations via Identifying Important Utterances, in Proceedings of the 28th International Conference on Computational Linguistics, pp. 717–729, Barcelona, Spain (Online) (2020), International Committee on Computational Linguistics
- [Sun 19] Sun, K., Yu, D., Chen, J., Yu, D., Choi, Y., and Cardie, C.: DREAM: A Challenge Data Set and Models for Dialogue-Based Reading Comprehension, Transactions of the Association for Computational Linguistics, Vol. 7, pp. 217–231 (2019)
- [Zhang 20a] Zhang, T., Kishore, V., Wu, F., Weinberger, K. Q., and Artzi, Y.: BERTScore: Evaluating Text Generation with BERT, in International Conference on Learning Representations (2020)
- [Zhang 20b] Zhang, Y., Jiang, Z., Zhang, T., Liu, S., Cao, J., Liu, K., Liu, S., and Zhao, J.: MIE: A Medical Information Extractor towards Medical Dialogues, in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 6460–6469, Online (2020), Association for Computational Linguistics
- [Zhang 20c] Zhang, Y., Sun, S., Galley, M., Chen, Y.-C., Brockett, C., Gao, X., Gao, J., Liu, J., and Dolan, B.: DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation, in ACL, system demonstration (2020)
- [Zhang 21a] Zhang, S., Celikyilmaz, A., Gao, J., and Bansal, M.: EmailSum: Abstractive Email Thread Summarization, in Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pp. 6895–6909, Online (2021), Association for Computational Linguistics
- [Zhang 21b] Zhang, Y., Ni, A., Yu, T., Zhang, R., Zhu, C., Deb, B., Celikyilmaz, A., Awadallah, A. H., and Radev, D.: An Exploratory Study on Long Dialogue Summarization: What Works and What’s Next, in Empirical Methods in Natural Language Processing (EMNLP) 2021 (2021)
- [Zhao 19] Zhao, W., Peyrard, M., Liu, F., Gao, Y., Meyer, C. M., and Eger, S.: MoverScore: Text Generation Evaluating with Contextualized Embeddings and Earth Mover Distance, in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 563–578, Hong Kong, China (2019), Association for Computational Linguistics
- [Zhao 21] Zhao, L., Zheng, F., He, K., Zeng, W., Lei, Y., Jiang, H., Wu, W., Xu, W., Guo, J., and Meng, F.: TODSum: Task-Oriented Dialogue Summarization with State Tracking (2021)
- [Zhong 21] Zhong, M., Yin, D., Yu, T., Zaidi, A., Mutuma, M., Jha, R., Awadallah, A. H., Celikyilmaz, A., Liu, Y., Qiu, X., and Radev, D.: QMSum: A New Benchmark for Query-based Multi-domain Meeting Summarization, in Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 5905–5921, Online (2021), Association for Computational Linguistics
- [Zhu 21] Zhu, C., Liu, Y., Mei, J., and Zeng, M.: MediaSum: A Large-scale Media Interview Dataset for Dialogue Summarization, in Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 5927–5934, Online (2021), Association for Computational Linguistics
- [Zou 21a] Zou, Y., Lin, J., Zhao, L., Kang, Y., Jiang, Z., Sun, C., Zhang, Q., Huang, X., and Liu, X.: Unsupervised summarization for chat logs with topic-oriented ranking and context-aware auto-encoders, in Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35, pp. 14674– 14682 (2021)
- [Zou 21b] Zou, Y., Zhao, L., Kang, Y., Lin, J., Peng, M., Jiang, Z., Sun, C., Zhang, Q., Huang, X., and Liu, X.: Topic-oriented spoken dialogue summarization for customer service with saliency-aware topic modeling, in Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35, pp. 14665–14673 (2021)