こんにちは、RevComm にて主に MiiTel の音声解析機能に関する研究開発を担当している石塚です。
石塚賢吉(いしづか けんきち)
プリンシパルリサーチエンジニア。筑波大学大学院博士後期課程卒業。博士(工学)。日本HP株式会社にて通信事業者向けのシステム開発、株式会社ドワンゴで全文検索システムの開発などに従事。2019年12月、株式会社RevComm入社。音声認識、音声感情認識、全文検索システムの研究開発を行なっている。
→ 過去記事一覧
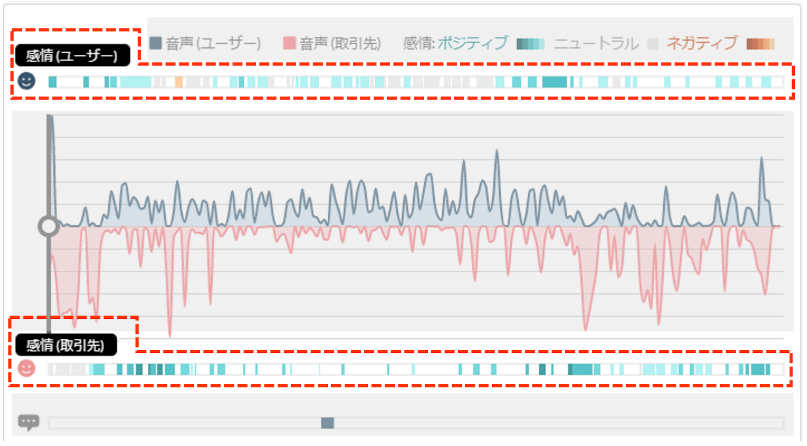
RevComm では、電話営業やお客様対応を可視化する音声解析 AI 搭載型のクラウド IP 電話 MiiTel (ミーテル) を提供しています。
2022年2月9日、その MiiTel に音声感情認識機能を追加しました。
これによって話し手のポジティブ、ネガティブな感情が可視化され、会話の当事者以外でも感謝を伝える様子やクレームなどに気づくことができます。
ビジネスの電話応対について、話者の発話音声の感情の側面からの解析を可能とするため、RevCommでは音声感情認識の研究を重ねてきました。成果の一部は国立大学法人筑波大学との共同研究による音声感情認識に関する論文として、2021年8月に音声処理系トップカンファレンス「INTERSPEECH 2021」にて発表しています。
今回は、INTERSPEECH 2021で発表した論文
「Speech Emotion Recognition based on Attention Weight Correction Using Word-level Confidence Measure」
について解説します。
1. はじめに
深層学習技術が発展し、時系列データを扱うリカレントニューラルネットワークや Self-Attention による重み付けの技術が音声からの特徴抽出に有効に機能し、音声感情認識の性能が向上してきました [Mirsamadi, 2017]。また、音声認識により得られたテキストと音響特徴量の両方を利用して、高精度な音声感情認識を達成しようとする研究もあります。
しかし、音声認識による文字起こしの精度はまだ十分とは言えません。特に、文法が崩れがちな感情を含む音声を音声認識で正確に文字起こしするのは困難です。そこで、音声感情認識モデルと事前学習された音声認識モデルを End-to-end で結合し、感情音声データセットを用いたマルチタスク学習でファインチューニングすることで、認識精度を向上する方法などが提案されています [Feng, 2020]。しかしこの方法では、感情音声データセットに対して音声認識と音声感情認識を行うモデル全体をファインチューニングするために計算コストがかかります。本研究では、音声認識により得られるテキストの信頼度の情報を用いて、音声認識の誤りの影響を軽減しながら音声感情認識を行うための手法を提案します。
2. 提案手法
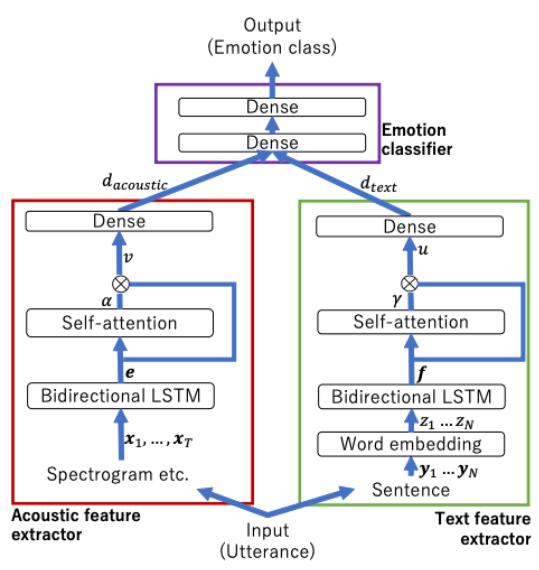
2.1 提案アルゴリズムのベースとなる音声感情認識器の構造
図1に提案アルゴリズムのベースとなる、テキスト情報と音響情報を用いた音声感情認識器の構造を示します [Mirsamadi, 2017] 。本音声感情認識器は、音響特徴抽出器、テキスト特徴抽出器、そして2つの抽出器の出力を組み合わせて最終的な分類を行う感情分類器の3つから構成されています。本アルゴリズムでは、まず発話音声から音響特徴量とテキスト特徴量を抽出します。次に、音響特徴量を BiLSTM に入力し、Self-Attention を用いて重み付けを行い、中間表現を得ます。テキスト特徴量は、Word-Embedding によりベクトル化し、 音響特徴量と同様に処理します。最後に、中間表現を連結し、完全連結ネットワークで分類することで、最終的な感情クラスが出力として得られます。 本研究では、この音声感情認識器の構成をベースとし、Self-Attentionの重みを単語レベルの単語信頼度で補正することで、音声認識時に誤認識された単語に Self-Attention で注目する事を防ぎ、音声感情認識精度の向上を目指します。
2.2 単語信頼度とは
単語信頼度とは、音声認識結果の単語ごとの信頼度を0.0 - 1.0の値で表現したものです。表1に、正解文の単語と音声認識結果の単語と単語信頼度の例を示しています。表1の赤で塗りつぶされた箇所は誤認識された単語で、基本的には、誤認識された単語の信頼度は低くなる傾向があります。ただし、黄色で塗りつぶされた箇所のように、正しく認識された単語の場合でも信頼度が低くなることがあります。
| 正解文 | I | NEED | YOUR | BIRTH | CERTIFICATE |
| 音声認識結果 (単語信頼度) | I (1.0) | READ (0.5) | YOUR (0.3) | BURST (0.4) | CERTIFICATE (1.0) |
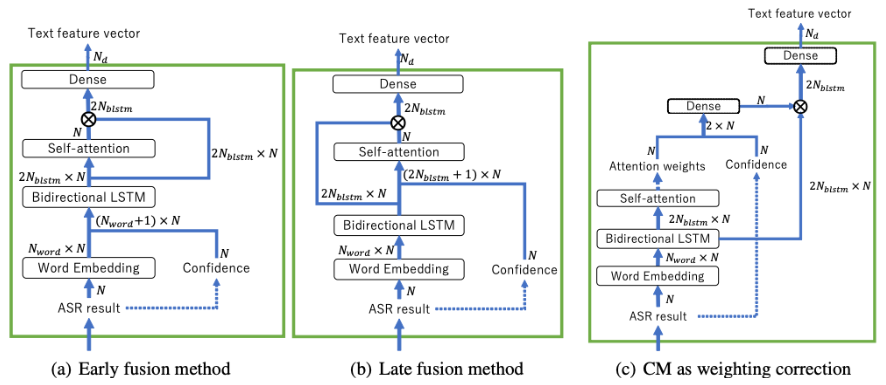
音声感情認識のテキスト特徴量として単語信頼度を用い、誤って認識された単語の影響を抑制したり、正しく認識された単語の影響を強調したりすることを考えます。本論文では、テキスト特徴抽出器での単語信頼度の利用方法として、図2のような3つの構成で単語信頼度の有効性を比較します。
- Proposed (a) Early fusion method: 単語信頼度をテキストの特徴量と組み合わせて、テキスト特徴量の一部として使用する構成
- Proposed (b) Late fusion method: 単語信頼度を中間特徴量と組み合わせて使用する構成
- Proposed (c) Confidence Measure (CM) as weighting correcting: 単語信頼度をアテンション重みと組み合わせて使用する構成です。こちらは、前の二つの構成に対して、単語信頼度のテキストの特徴に対する依存が小さくなることが期待されます
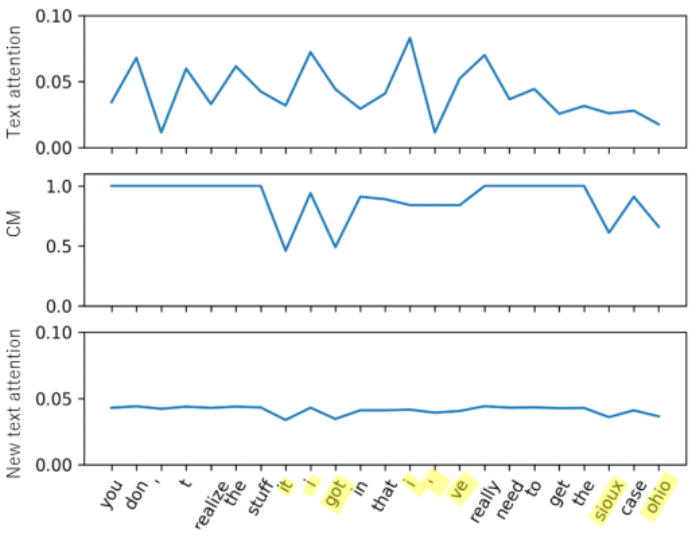
次に、Proposed (c) の構成において、単語信頼度がアテンションの重みに対してどのように作用するかについて図3を例に説明します。図3において、横軸は時間軸となっており、音声認識結果のテキストが下部に示されています。上から一番目の折れ線グラフは、補正前の単語に対するアテンションの重みを表現したものです。二番目は、単語信頼度であり、黄色で塗りつぶされた部分に音声認識誤りの単語列があったとして、その部分の単語信頼度が低くなっています。三番目は、補正後のアテンションの重みです。このとき、音声認識の誤り部分のアテンションの重みが、単語信頼度で補正され、小さくなっていることがわかります。逆に、単語信頼度の大きな部分のアテンションの重みは、大きくなります。
3. 評価実験
本研究では、感情認識のベンチマークデータセットの一つである Interactive Emotional Dyadic Motion Capture (IEMOCAP) データセット[Busso, 2008] を利用して、提案手法の有効性を評価します。IEMOCAP データセットでは、合計10人の話者(男性5人、女性5人)による各発言に対し、人手での書き起こしテキストと7つの感情(幸せ、悲しい、中立、怒り、興奮、欲求不満、その他)ラベルのどれかが1つ付与されています。評価実験では 5-fold cross validation を行い、話者の独立性を確保しながら音声感情認識の精度を評価します。
| Method | UA | WA |
| Speech | 61.1 | 64.3 |
| Text (Transcript) | 75.5 | 75.6 |
| Text (ASR) | 71.8 | 71.9 |
| Speech + Text (Transcript) | 78.6 | 78.4 |
| Speech + Text (ASR) | 73.9 | 74.2 |
| Our Proposed Method | ||
| Proposed (a) | 74.3 | 74.4 |
| Proposed (b) | 74.9 | 75.4 |
| Proposed (c) | 75.9 | 76.1 |
使用する特徴量の組み合わせを変えた音声感情認識の実験結果を表 2 にまとめています。IEMOCAP データに対する音声認識テキストの Word Error Rate(WER)は43.5%でした。音声感情認識の評価指標として、先行研究に従い、Unweighted Accuracy(UA)および Weighted Accuracy(WA)を採用していますが、両評価指標は類似した傾向を持つため、主にWAを用いて結果を分析します。
音声のみを用いたとき [Speech] の WA 値は64.3%であり、人手での書き起こしのみを用いたとき [Text(Transcript)] の WA 値は75.6%となりました。音声と人手での書き起こしテキストを組み合わせたとき [Speech+Text(Transcript)] の WA は78.4%であり、音声のみ [Speech] よりも14.1%、人手で書き起こしたテキストのみ [Text(Transcript)] よりも2.8%上回りました。一方、人手で書き起こしたテキストを使う代わりに音声認識結果を用いると [Text(ASR)]、WA が3.7%低下することがわかりました。
音声と音声認識結果の組み合わせ [Speech+Text(ASR)] では WA が74.2%となり、4.2%の性能劣化となりました。
単語信頼度をテキスト特徴量に組み込む手法として提案した Proposed (a): Early fusion、Proposed (b): Late fusion、Proposed (c): CM as weighting correcting については、それぞれ74.4%、75.4%、76.1%のWAが得られました。提案した手法のうち Proposed (c): CM as weighting correcting は、[Speech+Text(ASR)] からの性能向上が最も大きく、音声と人手での書き起こしテキストを組み合わせた手法の結果に最も近い性能を示しています。これは、単語信頼度でアテンションの重みを調整し、誤っている可能性の高い音声認識結果の単語の重要度を下げることで、性能向上が実現できることを示唆しています。

IEMOCAP データセットを用いた先行研究の実験結果と本研究の提案手法の実験結果の比較を表3にまとめています。提案手法は、最も高い UA と WA を達成しました。
4. まとめ
本研究では、音声認識により得られるテキスト情報と単語レベルの信頼度を利用する音声感情認識手法を提案しました。そして、感情音声データセット IEMOCAP を用いて、単語信頼度により音声認識テキストの音声認識誤りの影響を軽減する手法について検討しました。提案した3つの手法のうち、単語信頼度をSelf-Attentionの重みの補正として用いる方法が最も良い性能を得ることができました。そして、IEMOCAP データセットを用いた先行研究の多くと比較して、提案手法がより良い性能を示すことがわかりました。
「Speech Emotion Recognition based on Attention Weight Correction Using Word-level Confidence Measure」の本文はインターネット上で無料公開されているので、詳しくはこちらをご覧ください。また、RevComm では ICASSP(International Conference on Acoustics, Speech, & Signal Processing)2022でも京都大学との音声感情認識についての共同研究の成果を発表しておりますので、興味があればぜひこちらもご覧ください。こちらの研究では、マルチタスク学習を用いて、RevCommが保有するビジネス電話応対の自然な感情音声データセットと、演技された感情音声のデータセットを組み合わせて、より効果的に音声感情認識モデルを学習する手法について提案しています。
今後も、共同研究で得られた成果をもとに音声感情認識モデルを強化し、弊社プロダクトに組み込むことで、お客様の感情の可視化や、お客様の不満を示す対話の抽出と解析などへの応用に取り組んでいきます。RevComm は AI 技術領域にイノベーションをもたらし、コミュニケーションをより豊かにしていくことを目指しています。そのために、今後も音声・言語・画像の領域に関わる研究開発を推進し、国内外へ積極的に学術的な貢献を行っていきます。
5. 参考文献
[Mirsamadi, 2017] S. Mirsamadi, E. Barsoum, and C. Zhang, “Automatic Speech
Emotion Recognition Using Recurrent Neural Networks with Local
Attention,” Proc. ICASSP, pp. 2227-2231, 2017.
[Feng, 2020] H. Feng, S. Ueno, and T. Kawahara, “End-to-End Speech Emotion
Recognition Combined with Acoustic-to-Word ASR,” Proc. Interspeech pp. 501–505, 2020.
[Busso, 2008] C. Busso, M. Bulut, C. Lee, A. Kazemzadeh, E. Mower, S. Kim, J. N. Chang, S. Lee, and S. S. Narayanan, “IEMOCAP: Interactive Emotional Dyadic Motion Capture Dataset,” Language Resources and Evaluation, vol. 42, no. 4, pp. 335-359, 2008.