はじめに
RevCommの宇佐美です。
RevCommでは、音声解析AI電話「MiiTel(ミーテル)」やAI搭載オンライン会議解析ツール「MiiTel Meetings」を開発・提供しています。
私はMiiTelの認証基盤 (MiiTel Account) 開発チームで、Project Manager兼Sortware Engineerとして活動しています。
過去記事:
- Cognito user pool で OpenID Connect を利用した外部 ID Provider によるサインインを実現する - RevComm Tech Blog
- Webアプリケーションの国際化対応をバックエンドからフロントエンドに移行した話 - RevComm Tech Blog
今回は、MiiTel Accountというサービスを安定的に運営するためにどのような取り組みをしているのか、SLO (Service Level Objective) と絡めて紹介したいと思います。
SLOとは何か
SLOは直訳すると"サービス信頼性目標"です。
一般的に、Webサービスやシステムを提供している会社は、ユーザーによりよい体験を提供するため障害を最小限に抑えるよう努力しています。
ただシステムである以上、サービスは常に100%の信頼性を持って稼働できるというわけではなく、どうしても時々障害やシステム不具合が発生します。そこで登場するのがSLOです。
SLOは、サービス提供者(例えばMiiTelのようなWebサービスを提供する会社)が設定するサービスの品質目標です。これは、ユーザーがサービスを利用する際に期待する品質レベルをもとに表現されます。
実際のSLOは、正確な数字で表現されます。例えば、99.9%の正常稼働時間を保証するとか、全リクエストのうちの99.9%のレスポンスタイムを2秒以内に維持する、のような形です。これらは顧客がサービスをどれだけ快適に利用できるかを評価するための指標です。
関連用語 - SLIとSLA
SLOに関連して、SLI (Service Level Indicator) とSLA (Service Level Agreement) もよく似ていますが重要な概念です。
SLI (Service Level Indicator) : サービスの性能や品質を測定する具体的かつ定量的な指標です。例えば、平均応答時間やエラー率などが含まれます。
SLA (Service Level Agreement): サービス提供者と顧客との間で合意される契約ないし取り決めです。通常、サービスの提供者が顧客に対してどの品質指標をどのくらい満たすべきかが明記され、目標が満たされなかった場合の補償を含みます。
SLO (Service Level Objective): SLOはSLIに基づいて設定される品質目標であり、サービスの性能や品質を具体的な目標数値で設定します。内部的な目標として使われることが多いですが、サービスによっては公表されています。
まとめると、SLIはサービスの定量的な状態を示し、SLAはサービス提供者と顧客の合意事項を定義し、SLOはサービスが達成すべき品質目標を設定する役割を果たします。これらの指標が、サービス提供者と顧客の信頼性を高める鍵となっています。
Google CloudのWebサイトでは、下記のようにSLOとSLIの差がわかりやすく図で示されています。
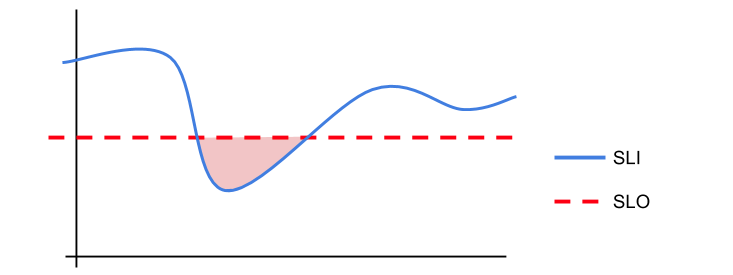
SLO を定義する | アーキテクチャ フレームワーク | Google Cloud
ここからはMiiTel AccountがどのようにSLOを設定していて、その達成に向けて具体的にどんな取り組みをしているかをご紹介します。
MiiTel Accountの位置づけ
まず、MiiTelにおけるMiiTel Accountの位置づけについて説明します。
MiiTelの技術スタックとアーキテクチャ変遷を紹介します(2023年5月版) - RevComm Tech Blog
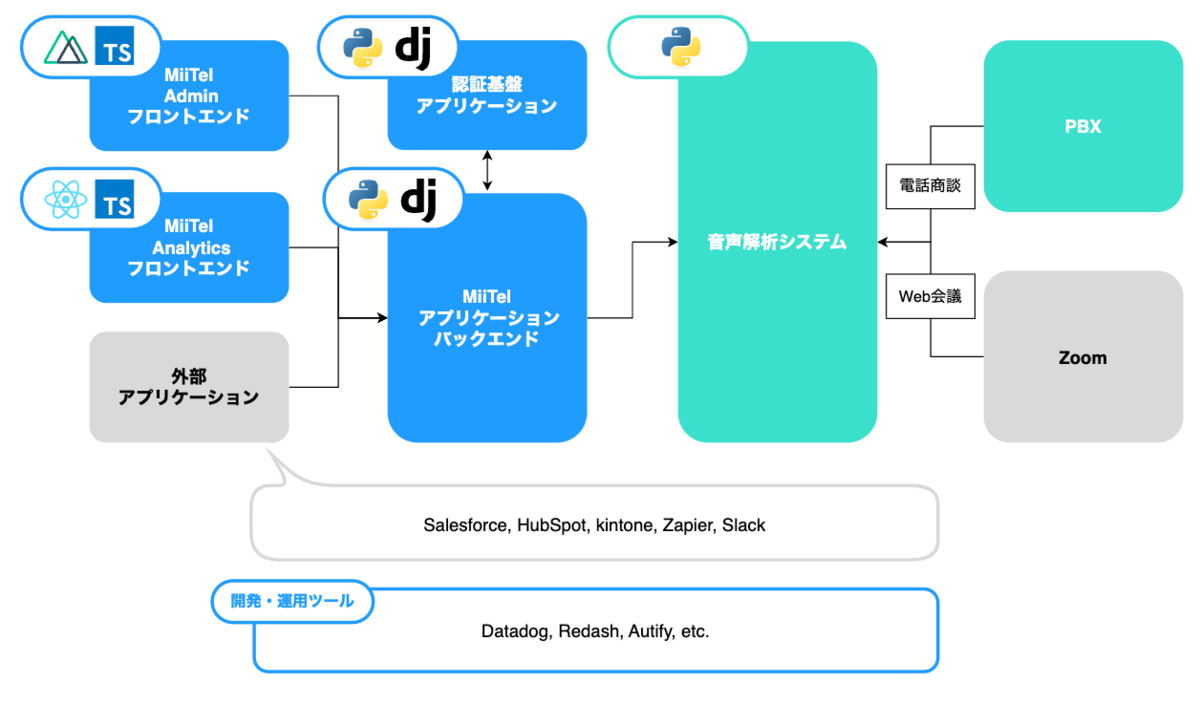
MiiTel AccountはMiiTel全体の認証機能を担っているため、もし障害が発生するとMiiTelを構成するどのサービスにもアクセスできません。MiiTelは通話や受電に使われるため、数秒のサービス停止であってもユーザーに大きな影響を及ぼしてしまいます。
そのため、何よりも堅牢かつ安定的に稼働することが求められるサービスだといえます。ただ一方で、認証関連の機能追加もビジネス的なニーズによって迅速に行なっていく必要があり、ここでサービスの安定稼働とのジレンマが生じます。
これをうまくコントロールするために使える枠組みがSLOです。
通常のサービスよりも高いSLOを設定することで安定稼働を担保しつつ、SLOが達成できていて余裕があるうちは、ある程度攻めの機能追加開発も可能になります。
SLOという形で目標を明確化するとともに、サービスの性能や品質についての現状を可視化しながら運用することによって、安定稼働と機能追加の緊張関係をある程度緩和することができます。
MiiTel AccountにおけるSLO
ではMiiTel Accountでは、実際にどのようなSLOを設定しているのでしょうか。
MiiTelではモニタリングツールとしてDatadogを活用しており、ここで今は以下のような目標値を設定しています。
- 総リクエスト数における5XXエラーの割合が0.2%以内
- レスポンスタイムの平均値が3秒以内
*いずれも直近90日以内の99.9%以上で上記を満たすこと
かなりシビアな数字ではありますが、2023年10月現在の実績値としてはエラーの割合のほうが99.999%、レスポンスタイムの方は100%と目標を達成しています。エラーバジェットにもかなりゆとりがあるため、ある程度積極的な機能開発ができる状態を保てています。


Datadogは、APM (Application Performance Monitoring) を入れておけばSLOの設定も容易で、こういったモニタリング数値なども自動で計算してくれて、アラートの設定も思いのままなので非常に便利です。
SLO 達成に向けた取り組み
SLOを保つためには、様々な取り組みや運用上の工夫が必要です。ここからは、MiiTel Accountでの取り組みの一部を紹介します。
各種メトリクス・モニタリングアラートの設定
まず簡単にできてかつ効果が高いものとして、メトリクスやモニタリングアラートの設定があります。これは色々なツールで実現できますが、上記のとおりRevCommではDatadogを監視ツールとして使っています。
リクエスト数に異常値があった場合や、AWSなどのインフラのメトリクスが通常より逼迫している場合などに、閾値を設定してSlackなどにアラートを送るように設定することができます。
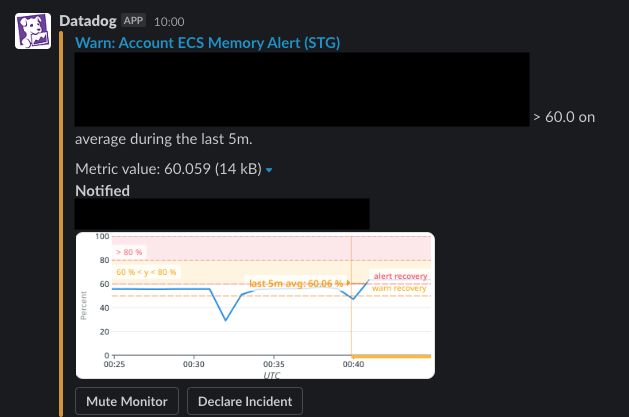
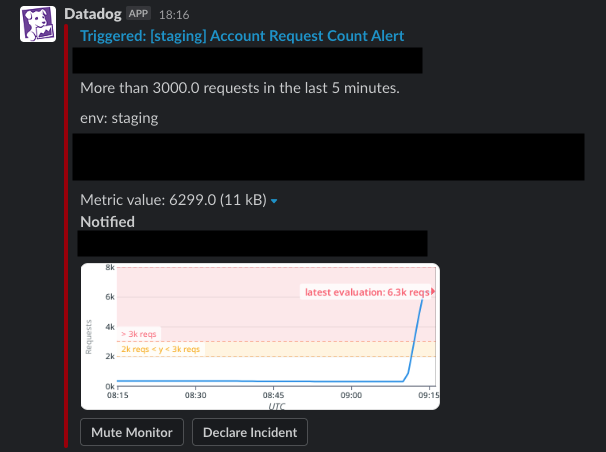
アラートを設定する場合は、本番環境とそれ以外の環境の通知チャンネルを分けておくと、至急対応が必要なものかどうかわかりやすく、開発環境のアラートで埋もれてしまうことも避けられるのでおすすめです。
定例ミーティングでのメトリクスチェック
MiiTel Accountチームでは週に2回の定例ミーティングを行っており、タスクの進捗状況や相談・共有事項などについて会話します。
普段からSLOや各種メトリクスについて意識するため、ミーティングの冒頭で毎回DatadogのSLOダッシュボードをチェックしています。
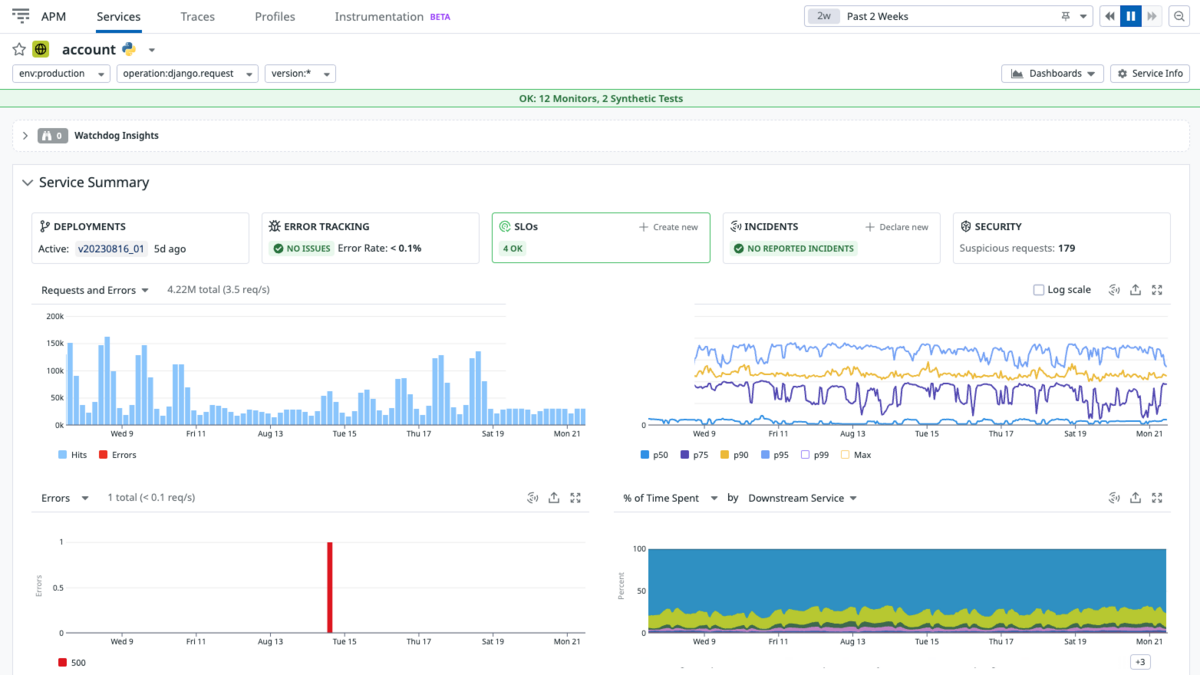
場合によってはAPIエンドポイントごとのリクエスト数の推移や、レスポンスタイムなどを分析して、改善が必要な場合にこのデータを元に効果的な施策を検討することもあります。また、ときにはこの定例ミーティングでのチェックから異常が見つかることもあります。
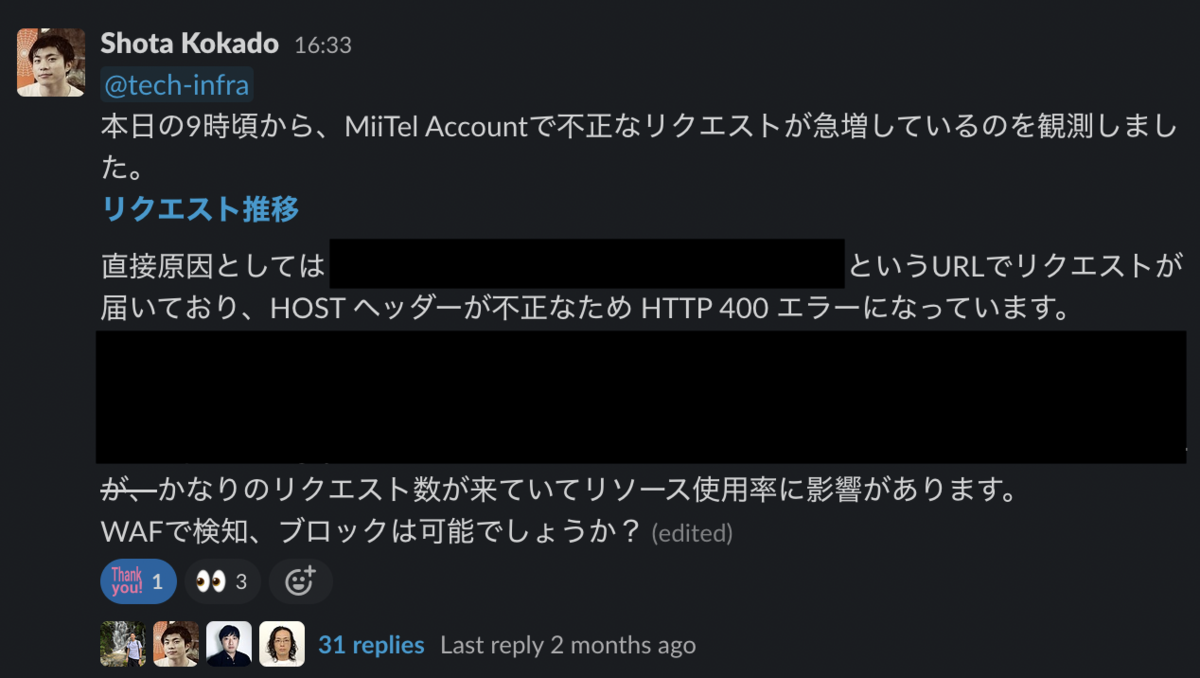
これは、過去に何度かこのブログでも登場している Shota Kokado (@skokado) (過去記事: Amazon Inspectorによるプラットフォーム診断とコンテナイメージ改善の取り組み - RevComm Tech Blog) が気づいてくれた事例です。
このときはまだ前述のリクエスト数アラートを設定していなかったのですが、定例ミーティングでのダッシュボードチェックで通常時の10倍ほどの異常なリクエスト増が確認されました。
Webサーバーのオートスケーリングなどのおかげでサービスへの顕著な影響はなく、結果的にはWAFなどのブロックによって対応できました。もしすぐに発見されていなければ、どこかでインフラのリソースが逼迫してサービスに影響が出ていた可能性があります。
リリース後のインテグレーションテストと E2E テストの自動化
監視やモニタリングを充実させることも重要ですが、一方で障害の多くはリリース直後に起きることが多いです。また、実環境やデータベースを使わないとユニットテストでは気づけないようなバグなどが混じっていることもあります。
MiiTel Accountではこういったリスクを低減するため、リリース後のAPIインテグレーションテストとE2Eテストを自動実行するようにしています。これは各環境 (大きく分けて3つの環境があります) ごとに設定しており、本番リリース前に予期しないバグなどが起きていないかどうか確認することができます。
- インテグレーションテスト: ほぼ全APIエンドポイントへの正常系テスト
- E2Eテスト: Autifyを使ったクリティカルな機能のUIテスト
テストが完了すると、それぞれ以下のようにSlackに通知が来ます。
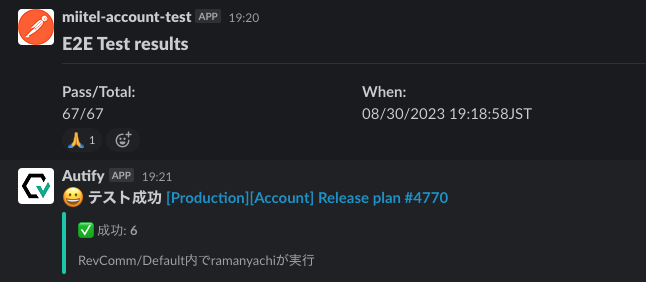
このあたりの自動実行の仕組みは Raman Yachi (@r-ym) が構築したもので、最近ブログにまとめてくれているので、詳細はこちらをご覧ください。
- E2E Testing system for MiiTel Account - RevComm Tech Blog (English)
- MiiTel AccountチームのE2Eテスト自動化 - RevComm Tech Blog (日本語)
この仕組みによって手作業で動作確認する手間がかなり省けたため、より安全かつ心理的な負担も少ない中でリリースが行えるようになりました。
これらのテストで安全性がかなり担保されるようになったため、元々週次夜間に行っていたリリース作業を現在は日中随時に行うよう切り替えています。
デプロイ頻度はDevOps Research and Assessment (DORA) のFour keys metricsでも特に重要視されている指標なので、SLOだけではなく開発生産性という意味でも大きな意味がある施策だったと考えています。
今後に向けて
以上のような施策によって、幸運にも今のところはSLOを達成したうえでさらに高い水準の指標をキープできています。
Webシステムを運営していく以上は障害やサービスのパフォーマンスが一時的に落ちることは避けられない面もありますが、これまで述べてきたような施策によってこのリスクをコントロールしつつ、高い生産性を保って新機能開発を続けていくこともできるはずです。
今後はSLOを保ったまま、さらに指標を充実させてより詳細なサービスのヘルスチェックができるようになったり、開発生産性を向上させていくことを目指しています。
RevCommでは機能開発だけではなく、こういった運用面の知見を深めたり新しい取り組みを行う機会が豊富にあります。興味がある方は、下記から採用情報をチェックしてみてください。