Research Engineerの大野です。 新しいスライドを公開したのでご紹介します。
スライドの概要
ここでは、機械学習モデルの学習の際のメモリ要件を下げることができる、Low-Rank Adaptation (LoRA) の評価を行いました。
言語モデルの大きさが加速度的に増えており、それに伴いハードウェアの要件が大きくなっています。第1回LLM勉強会の資料の図を下記に引用し、近年に作成された言語モデルのパラメータ数を示します。

評価では、対話要約のデータセットである[Gliwa 19]のSAMSumコーパス(コーパスへのリンク)を使用し、ファインチューニングに必要な時間とGPUメモリを計測しました。また、ROUGEスコアを使用してそのモデルの性能を評価しました。実験では、NVIDIA A10G Tensor Core GPUを持つAWS EC2のg5.xlargeを使用しました。
スライドの結論
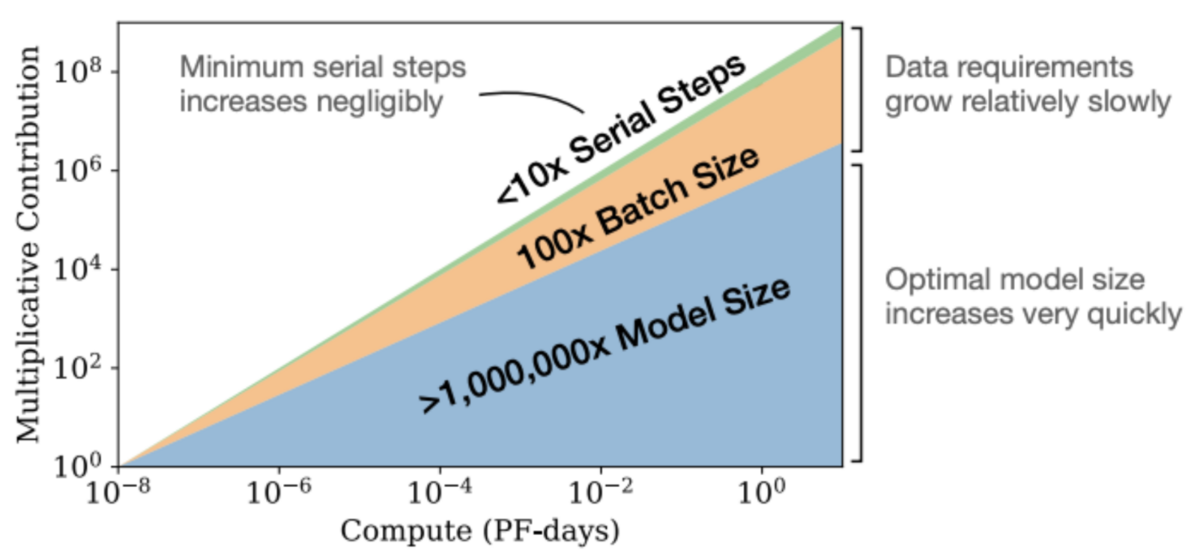
評価の結果、LoRAを使用することで、ファインチューニングに必要なメモリが低減することを確認しました。また、同じデータ量を使用した場合には、大きなモデルが小さなモデルと比べて性能が高いことも確認しています。このことは[Kaplan 20]でも示されています。
LoRAの関連研究はこのスライドの中で扱っていません。[Lialin 23]や[Hu 23]が関連研究をまとめていますので、興味がある方がいらっしゃいましたらご確認ください。これらに載っていない関連研究では、[Zhang 23]や[Dettmers 23]が注目を集めています。
引用
- [Dettmers 23] Dettmers, T., Pagnoni, A., Holtzman, A., and Zettlemoyer, L.: QLoRA: Efficient Finetuning of Quantized LLMs (2023)
- [Gliwa 19] Gliwa, B., Mochol, I., Biesek, M., and Wawer, A.: SAMSum Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization, in Proceedings of the 2nd Workshop on New Frontiers in Summarization, pp. 70–79, Hong Kong, China (2019), Association for Computational Linguistics
- [Hu 23] Hu, Z., Lan, Y., Wang, L., Xu, W., Lim, E.-P., Lee, R. K.-W., Bing, L., and Poria, S.: LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models, arXiv preprint arXiv:2304.01933 (2023)
- [Kaplan 20] Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D.: Scaling Laws for Neural Language Models (2020)
- [Lialin 23] Lialin, V., Deshpande, V., and Rumshisky, A.: Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning (2023)
- [Zhang 23] Zhang, R., Han, J., Zhou, A., Hu, X., Yan, S., Lu, P., Li, H., Gao, P., and Qiao, Y.: LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init At- tention (2023)