著者: Researchチーム 春日
1. はじめに
「レビューがいつまでも終わらない」「人によって指摘の粒度がバラバラ」「些細な指摘で心理的安全性が削られる」……。
開発規模の拡大や専門性が深まるにつれ、ドキュメントやコードのレビューにまつわる悩みは、どの現場でも尽きないテーマではないでしょうか。Bacchelliら*1の研究でも示されている通り、現代のレビューには単なる欠陥発見以上に「知識の共有」や「チームの認識合わせ」という高度な役割が期待されています。特に私たちResearchチームにおいては、プロジェクト完了後の最終レポート作成が重要な文化として定着しており、その際に質の高いドキュメントレビューが不可欠です。しかし、一般的なリモートワークの課題に加え、フルリモートを前提とする私たちのチームでは、レビュアーとの物理的・心理的な『距離』がより大きなコミュニケーションの壁となっています。その結果、文脈の共有や質の高いフィードバックの維持という課題*2がより顕著になっています。
また、Googleの「Project Aristotle*3」が明らかにしたように、チームのパフォーマンスを支えるのは「心理的安全性」です。レビューにおける攻撃的な指摘や不透明な基準は、この土台を揺るがしかねません。 そこで私たちResearchチームは、これらの課題への一手として最終レポートなどのレビュープロセス(特に一次レビュー)へのAI (LLM) 導入を検証しました。本記事では、実際にGeminiを活用したレビューフローを構築し、チームメンバーによる評価で明らかになった「AI導入の効果」と、そこから見えてきた「活用の勘所」を、実例とともに共有します。
想定読者
- コードレビューやドキュメントレビューの工数削減に関心があるエンジニア・研究者
- チームの心理的安全性を保ちながら、成果物の品質を上げたいマネージャー
- 業務プロセスへの生成AI導入・活用を検討している方
2. 現状の課題とAI導入の狙い
従来の人間が行うレビュープロセスは、どうしても属人的になりがちで、主に以下の3つの課題を抱えていました。
- レビュー工数の増大: 規模拡大や専門領域の細分化により、確認に時間がかかる。
- 指摘内容のばらつき: 担当者のスキルや気分によって指摘が異なり、一貫性が欠如する。
- 心理的安全性の低下: ネガティブなフィードバックが続くと、レビュアー・レビュイー双方がストレスを抱えやすい。
AIレビューによるソリューション
私たちは「一次レビューの自動化」としてAIを導入することで、人間が本質的な議論に集中できる環境を目指しました。これによって以下の利点があると予想されます。
- 工数削減: 単純なミス(Typo)や論理矛盾をAIが事前に修正指示。
- 品質の均一化: 常に一定の基準で、客観的なフィードバックが提供される。
- 心理的安全性の確保: AIからの指摘は感情的な抵抗が少なく、客観的な事実として受け入れやすい。
3. 関連研究: 学術界におけるAIレビューの現在地
今回の調査にあたり、私たちはまず学術論文の査読(ピアレビュー)プロセスにおいて、現在AIがどのように活用されているかを調査しました。そこから見えてきた「AIレビューの分類」と「透明性へのトレンド」について紹介します。
論文レビューにおけるAI活用の3つのフェーズ
Chenらのサーベイ論文*4によると、論文レビューにおけるAI活用は大きく3つのカテゴリに分類されます。
- Pre-Review(事前レビュー): 原稿の初期評価や、専門分野の特定、適切な人間のレビュアーとのマッチングなど、査読に入る前の準備作業を効率化するフェーズです。
- In-Review(レビュー中): レビューレポートの自動生成や、人間のレビュアーの支援を行うフェーズです。数値スコアの予測や、書面による評価コメントの生成が含まれます。
- Post-Review(事後レビュー): 論文採択後の影響度評価(引用分析)や、プロモーション(要約や解説ビデオの生成)を行うフェーズです。
今回の私たちの取り組みは、レポートの品質向上とフィードバックの提供を目的としているため、この中の 「In-Review」 領域に位置づけられます。
AIによる採択予測の可能性と限界
「AIは論文の良し悪しを判断できるのか?」という問いに対して、興味深いデータがあります。 ICLR 2022の論文データセットを用いた研究("The AI Scientist")*5では、GPT-4oを使用したAIモデルが、論文の採択・不採択を70%程度の精度で予測できたと報告されています。また、本来採択されるべき論文を不採択にしてしまう「偽陰性率」に関しては、人間よりも低い値(つまり見落としが少ない)を記録しました。さらに、AI(LLM)が算出した評価スコアは、無作為に選んだ一人の人間のスコアよりも、「人間のレビュアー全員の平均スコア」に近いという結果が示されました。これは、人間とAIの「評価の性質の違い」を浮き彫りにしています。人間の場合、どうしても「その人の好み」「その時の気分」「得意・不得意」といったバイアスが入ります。その結果、ある人は「満点」を出し、別の人は「不合格」を出すといった具合に、誰が担当するかによって評価が大きくブレる(当たり外れがある)ことがあります。一方でAIは、個人のような強い感情や特定のバイアスを持ちません。そのため、特定の個人の意見というよりは、「審査員全員の意見をならした平均値(コンセンサス)」に近い、極端さのない安定した評価を導き出す傾向があります。 ただし、この手法をそのまま社内のレビューに適用することには慎重であるべきです。なぜなら、これらの成果は「明確なレビュー基準」と「大量の学習データ」が存在するコンペティション(学会)環境だからこそ実現できたものであり、社内のドキュメントレビューにそのまま転用するのは難しいためです。
レビューの透明化(Transparent Peer Review)
もう一つの重要なトレンドが、「レビュープロセスの透明化」 です。 これまで査読コメントは非公開が一般的でしたが、近年ではレビューコメントやそれに対する著者の返答も「論文の一部」とみなして公開する動きが広がっています。 例えば、世界的な学術誌であるNatureは、2025年から全ての新規投稿論文について、論文公開時に査読レポートと著者の回答を併せて公開すると発表しました*6。また、CS(コンピュータサイエンス)分野では OpenReview*7というプラットフォームが有名で、ここでは以前からレビューコメントが公開されています。
4. 実践したAIレビューの手法
今回私たちのAIレビューでは、Notionで書いたレポートのテキストを手動でコピーアンドペーストしたものを入力として、GoogleのGemini 2.5 Flashを使用してレビューを行いました。レビュープロセスにおいて工夫した点は「プロンプトのシンプルさ」と「透明性の確保」です。
プロンプト戦略
「レポートをレビューして不明な点を列挙してください。」
上記のような非常にシンプルな指示を採用しました。近年のLLMのサービスでは複雑な役割定義をしなくても、シンプルな指示で自動的に調整してくれるためです。
レビュープロセスの透明化
Nature誌などが採用している「Transparent Peer Review」の流れを参考にしました。 単にAIが修正案を出すだけでなく、「AIのレビュー指摘」に対して「著者がどう返答・修正したか」までをセットにしてドキュメント管理します。これにより、意思決定のプロセスが可視化され、ナレッジとして蓄積されます。
5. アンケート評価
私たちは実際にResearchチーム内でAIレビュー導入を行い、メンバー6名を対象にその有用性を評価するアンケートを実施しました。 定量評価は大きく「レビューの品質(Quality)」と「懸念点(Challenges)」の2つの軸で行われました。また、定性評価として幾つかの自由記述の質問項目を用意しました。
AIレビューの品質評価 (Quality of AI Review)
まず、AIによるレビューが業務にどの程度貢献したかを測るため、以下の6項目について5段階評価(1: 全くそう思わない 〜 5: 強くそう思う)を行いました。
- Q1. 有用性: AIのコメントは自分の仕事に役立ったか。
- Q2. 正確性: フィードバックは技術的・論理的に正確だったか。
- Q3. 提案の具体性: 改善提案は具体的で分かりやすかったか。
- Q4. 見落としの検出: 人間が見落としがちな点(Typoや規約など)を指摘できたか。
- Q5. 新規視点: 自分になかった新しい視点やアイデアを提供してくれたか。
- Q6. 品質の向上: 最終的な成果物の品質は向上したか。
▼ 評価結果
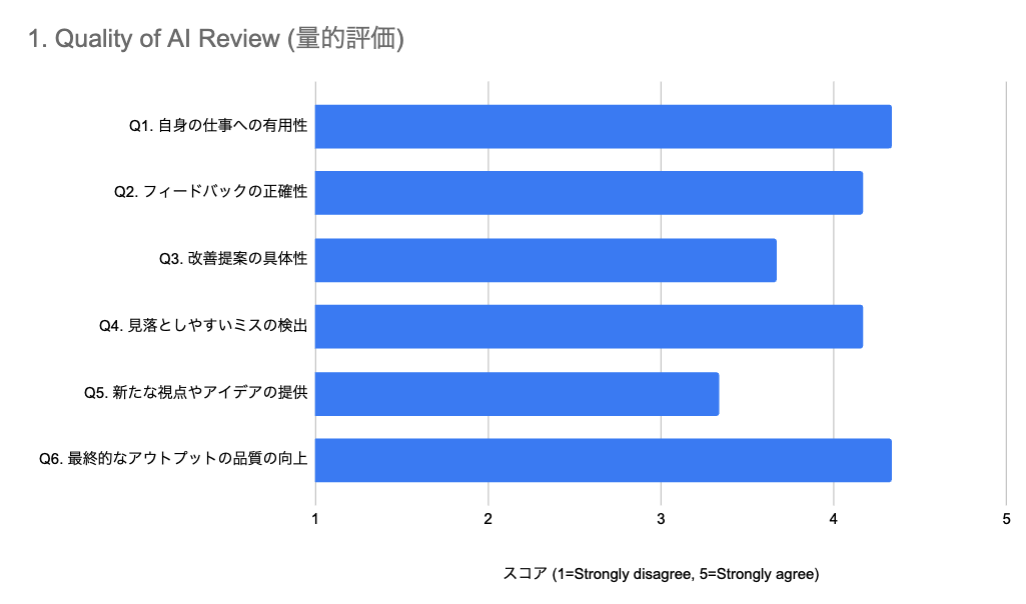
結果として、「Q6. 最終的なアウトプットの品質の向上」および「Q1. 自身の仕事への有用性」が非常に高いスコアを記録しました。特に、Typoや単純なミスといった「人間が見落としやすい点」の検出(Q4)についても高評価が得られています。 一方で、「Q3. 改善提案の具体性」や「Q5. 新たな視点やアイデアの提供」のスコアは相対的に低くなりました。 これについては、「欠点は指摘できるが、具体的な代案を出す能力はまだイマイチである」という現状が浮き彫りになりました。また、自由記述では「自分では思いつかないアイデアが出ることは稀だが、自分の考えに対する自信(裏付け)を持つ助けにはなる」といった意見も寄せられました。
AIレビューに対する懸念点 (Challenges and Concerns)
次に、AIをレビューに導入することに対する不安や懸念についても調査しました(複数回答可)。
▼ 質問項目と結果
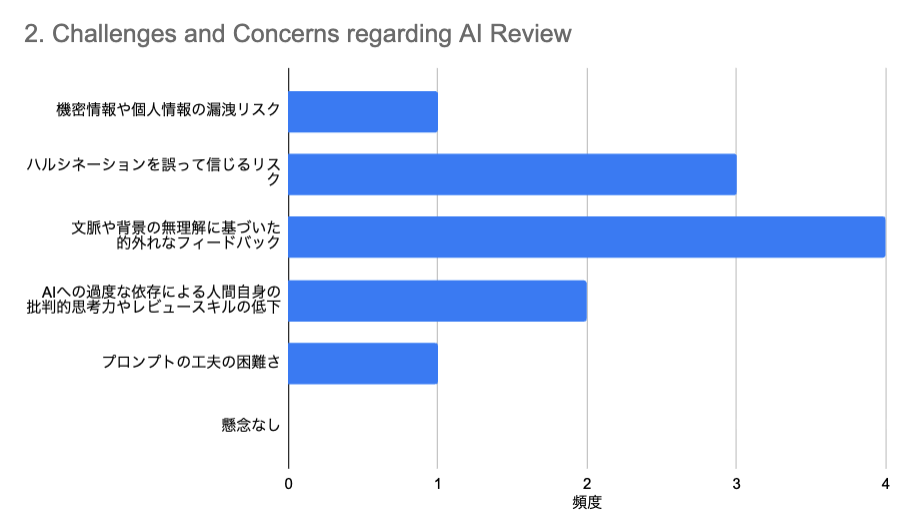
もっとも多かった懸念は「文脈や背景の無理解に基づいた的外れなフィードバック」でした。 レポートには書かれていない背景事情(例:実験を早く進めるためにあえて特定の条件を無視している等)をAIは理解できないため、指摘が的外れになるケースがあるという声が上がっています。この課題は、RAGによってある程度解消できると見込んでいます。 次いで多かったのが「ハルシネーション(もっともらしい嘘)を誤って信じるリスク」です。実際に「関連論文を教えて」と聞いた際に存在しない論文を捏造するケースも確認されており、情報の正確性には引き続き注意が必要です。 また、過半数は超えませんでしたが、「AIへの過度な依存による人間自身のレビュー能力の低下」を懸念する声もありました。 これらの懸念に加えて自由記述として、「AIのレビューの過信は避け、レビュイー自身が主体的に考える必要性」を唱えるコメントがありました。
AIレビューのこれから:現場の声と今後のロードマップ (Future Use of AI Review)
アンケートの最後には、今後のAIレビューに期待する機能や、具体的な活用方法についてのアイデア(Future Use)を自由記述形式でヒアリングしました。また、それらを踏まえた私たちの今後の技術的なロードマップについても共有します。
現場からの改善要望とアイデア
チームメンバーからは、AIをより実用的な「パートナー」にするための具体的な機能要望が多く寄せられました。
- 入力の強化(マルチモーダル化): テキストだけでなく、画像や表などの情報も読み込ませることで、より正確なレビューを実現したいという要望がありました。
- 擬似的なクロスチェック: 1つのAIだけでなく、レビューの観点が異なる複数のプロンプト(ペルソナ)を用意し、多角的な視点でチェックを行いたいというアイデアが出ました。
- 指摘から「修正」へ: 単に問題を指摘するだけでなく、具体的な修正案の雛形(ドラフト)までをAIに書かせることで、修正工数をさらに削減できる可能性があります。
- レビューの「甘さ」の改善: 「少し甘口すぎる」という意見もあり、プロンプトを変更することなどによって、より厳格なレビューにすることが求められています。
上記から、よりAIに正確かつ過不足なく情報を与え、より多角的・批判的・具体的なレビューをさせる工夫が必要であることが窺えます。
AIをレビューに活用することについてのその他のコメント
- AIレビューの限界: 現状ではAIはそのタスクやチーム・会社の方針に対する背景を十分に理解した上でのレビューができないため、今のところでは人間のレビュワーの完全な代替とはならないというコメントがありました。
- AIレビューの効率性: 人間がレポートやコードを細部までレビューするのは労力を要し、特に情報が不完全だったり読みづらい場合は多大な時間がかかります。AIによる事前レビューでレポートやコードをブラッシュアップすることで、大幅な労力削減が可能であるという、「レビュープロセスの前工程」としてのAI活用が推奨されていました。
- 小規模チームにおける利点: 現在の私たちのResearchチームのような小規模チームでは複数人によるダブルチェックやクロスチェックが難しいですが、AIを活用することで擬似的にこれらを実現できる利点も述べられていました。
- 主体的判断の重要性: 人間のレビューと同様に、AIの提案をそのまま受け入れることが常に最善とは限りません。レビュイーは自身で主体的に判断し、適切な改善を行う必要があることを戒める必要性があります。
- AIとの対話も「成果物」に: レポート提出時には、AIによるチェックとそれに対する修正履歴も含めて「レポートの一部」とみなす運用が推奨されていました。
6. 考察:AIは「優秀な校正者」だが「共著者」ではない
アンケート結果から導き出された、現段階でのAIレビュー活用のポイントは「適材適所」です。以下のようなAIの得意不得意を把握した上で、レビュイー自身が主体性を持つことが重要であると言えます。
活用のための3つの原則
今回の検証を通じて、私たちは以下の3原則を定めました。
- 鵜呑みにしない: 最終的な判断と責任は必ず人間が持つ(主体性の維持)。
- 得意を任せる: 機械的なチェック作業はAIに任せ、人間は本質的な設計や議論に集中する。
- 文脈を伝える: 重要な背景情報や制約条件がある場合は、プロンプトで可能な限り言語化して伝える。
今後の技術的ロードマップ
これらのフィードバックを受け、私たちはAIレビューの精度と深度を高めるために、以下の3つの方向性で開発・改善を進めていくことが考えられます。
- プロンプトエンジニアリングの深化: 現在のシンプルな指示から、レビュー観点をより明確化し、具体的かつ多角的なアクションプランを出力できるよう改善します。
- 外部情報(RAG)との連携: AIの最大の弱点である「文脈理解」を補うため、社内文書や関連文献を検索・参照させるRAG(Retrieval-Augmented Generation)の仕組みを取り入れます。
- マルチエージェントシステムの導入: 単一のAIではなく、異なる専門性や役割を持った複数のAIエージェントが協調してレビューを行う仕組み*8も有効である可能性があります。
7. おわりに
検証の結果、AIレビューはチーム全体の生産性と品質向上に確かに寄与することが確認できました。ただし、現状ではAIはあくまで「優秀な校正者」であり、人間のサポーターです。AIを「信頼しすぎず、上手に使いこなす」。 このバランス感覚を持つことで、私たちのレビュープロセスはより効率的で、創造的なものへと進化していくはずです。
参考文献
*1:Bacchelli, A., & Bird, C. (2013). Expectations, outcomes, and challenges of modern code review. Proceedings of the 35th International Conference on Software Engineering (ICSE).
*2:Sadowski, C., Söderberg, E., Church, L., Sipko, M., & Bacchelli, A. (2018). Modern Code Review: A Case Study at Google. Proceedings of the 40th International Conference on Software Engineering (ICSE).
*3:Google re:Work. (n.d.). Guide: Understand team effectiveness. (Project Aristotle).
*4:Chen, Q., Yang, M., Qin, L., et al. (2025). AI4Research: A Survey of Artificial Intelligence for Scientific Research. ArXiv, abs/2507.01903.
*5:Lu, C., Lu, C., Lange, R. T., et al. (2024). The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery. ArXiv, abs/2408.06292.
*6:Nature. (2025). Transparent peer review to be extended to all of Nature's research papers. Nature.
*7:OpenReview. https://openreview.net/
*8:D'Arcy, M., Hope, T., Birnbaum, L., & Downey, D. (2024). MARG: Multi-Agent Review Generation for Scientific Papers. ArXiv, abs/2401.04259.