
こんにちは、RevComm の玉城です。MiiTel Analytics のサーバーサイドの開発を主に担当しています。MiiTel Analytics は通話や会議の履歴・音声解析結果を集約し可視化する製品です。
MiiTel Analytics では以下の2つを提供するために Amazon OpenSearch を運用しています。
- 全文検索機能
- 使用単語頻度レポート
この Amazon OpenSearch のシャード数を切り替えるタイミングがありそちらを私が担当しましたので、その時の内容を紹介したいと思います。
シャード数切り替えに至った経緯
OpenSearch には MiiTel Analytics で解析された応対履歴が保存されます。そのため、MiiTel の利用ユーザーが増えると保存されるデータも増大し、書き込み/検索に掛かる負荷が大きくなっていきます。参考として、記事執筆時点では 1 億近いドキュメント数と 300 GB を超えるデータサイズとなっています。
このようにデータ数増大による負荷増大への対応として、OpenSearch にはインデックス毎にシャード数を設定します。シャードとは、OpenSearch でクラスターにデータを分散するときの単位です。
切り替え前のシャード数は 2 で各シャード数の容量は約 65 GB でした。AWS 側では適切なシャードのサイズは 10 〜 50 GiB にすることを推奨しており、既に推奨値を超えている状態でしたので早めの対応が必要でした。 そのため、今回の対応ではシャード数を 2 -> 4 に増やしてデータを分散させることで各シャード毎のサイズを 10 〜 50 GiB 以内に収めました。
参考: Amazon OpenSearch Service ドメインのサイジング - Amazon OpenSearch Service
リインデックスとは
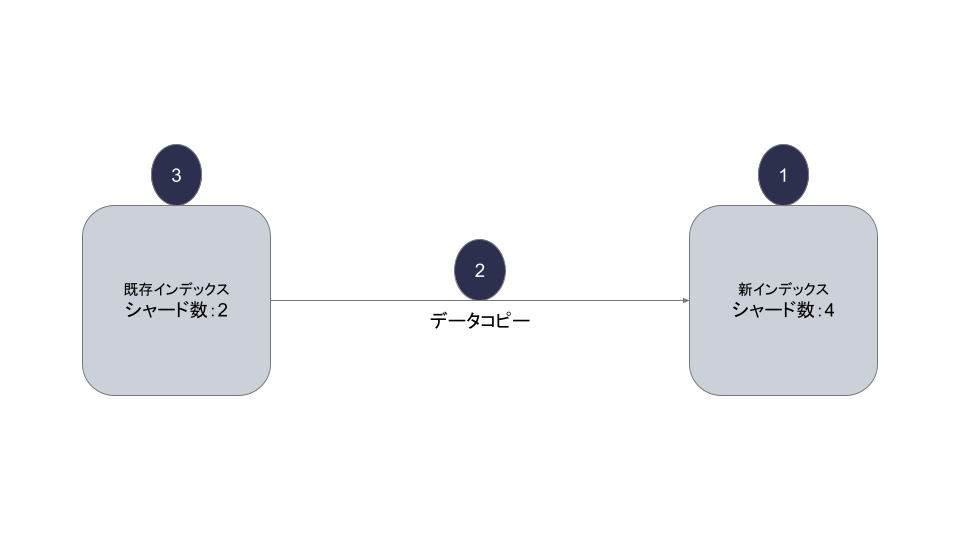
OpenSearch のシャード数設定はインデックス作成の際に行われます。既存のインデックスのシャード数を途中で変更することはできません。そのため、今回のシャード数切り替えのためにリインデックスを行いました。
リインデックスとは既存インデックスとは別に新しくインデックスを作成し、既存インデックスのデータをまるまる新しいインデックスにコピーすることです。この新しくインデックスを作成する際に、シャード数を 4 に設定することでシャード数切り替えの対応を行います。
- 新インデックスを作成します。その際に既存インデックスから更新したい設定値を新たに設定します。今回の場合はシャード数です。
- 既存インデックスから新インデックスに向けて Reindex API を実行します。
- 既存インデックスから新インデックスへエイリアスを変更し既存インデックスを削除します。
リインデックスの高速化
リインデックスを行う上で注意したい設定があります。それは refresh_interval です。refresh_interval はインデックスのドキュメント更新を検索に反映する操作の実行間隔になります。refresh_interval が 10 秒だった場合、下記の図のようにインターバルの間に起こった変更は次のインターバルにて検索ができるようになります。
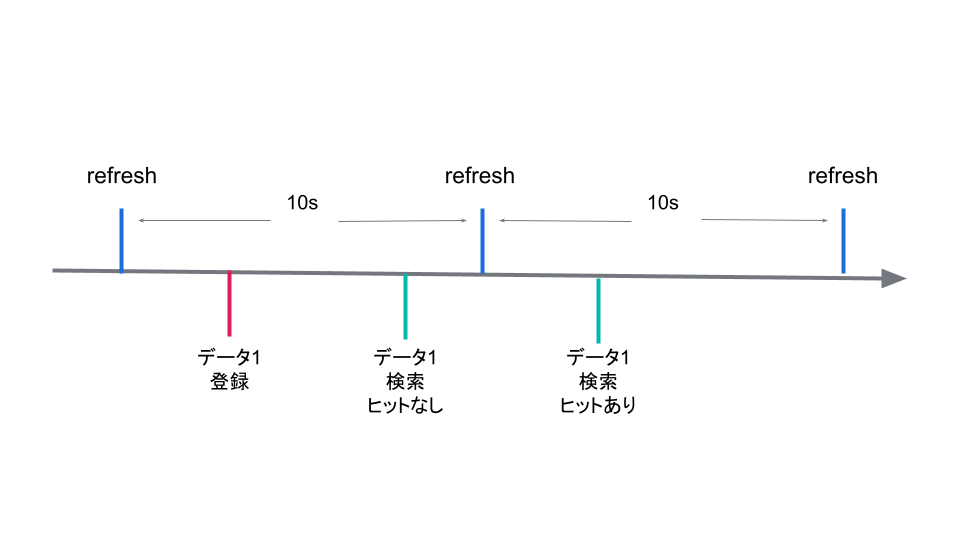
refresh_interval の設定を無効にすることでリインデックスの実行時間を早く終わらせることができます。詳細は後述しますが、今回のリインデックス作業中はデータの更新を一時的に止めることで、新しくデータが投入されない状況にすることができました。そのため、refresh_interval の設定を無効にすることができました。
例として約 110 万のドキュメント数に対して refresh_interval を -1(無効)と 100 秒で比較検証したところ、-1 の場合は 5 分 50 秒だったのに対して 100 秒の場合は 11 分 19 秒と倍近くの差が出ました。
MiiTel における OpenSearch へのデータ登録の仕組み
MiiTel Analytics で解析された応対履歴は Amazon RDS へ保存されます。OpenSearch へはこの Amazon RDS へデータが保存されたタイミングでデータが同期されます。
- 応対履歴を RDS へ保存/更新
- 保存/更新された応対履歴 ID を SQS に送信
- Lambda が応対履歴 ID を SQS より取得
- Lambda にて応対履歴を OpenSearch へ同期する API を呼び出す
- 同期 API のリクエストの応対履歴 ID を元に RDS より応対履歴を取得
- 取得した応対履歴を OpenSearch 用に変換し登録
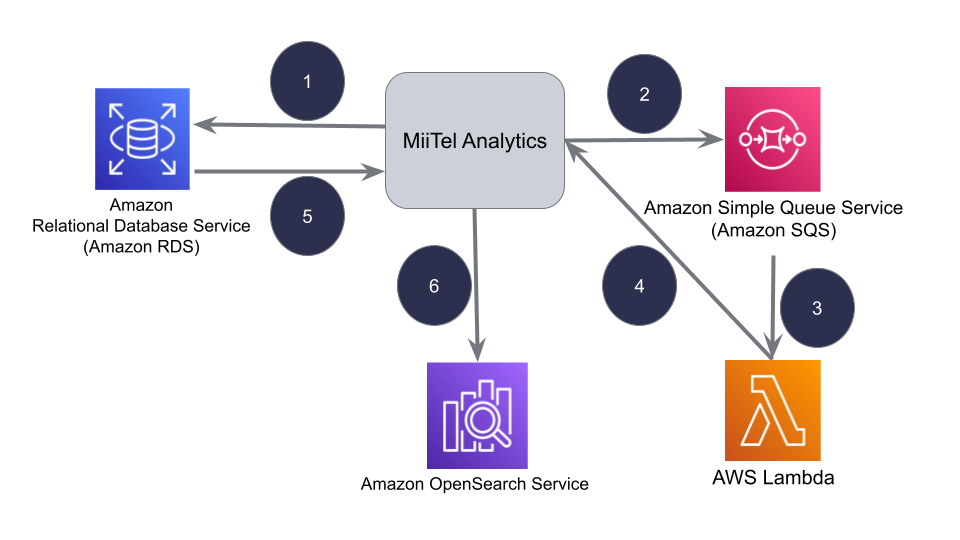
今回のリインデックス作業では上図の定期実行される Lambda を一時的に止めます。それによりリインデックス中は上図の 3 〜 6 が止まり、OpenSearch へのデータ追加/更新が行われないのでデータの不整合を防ぐことができます。
また、上図の 1 〜 2 はリインデックス中も稼働しているので SQS には新規または更新された応対履歴の ID が溜まっていきます。これらの応対履歴はリインデックスが完了した後に Lambda を再稼働することで OpenSearch へ登録されますので、リインデックス中の応対履歴も取り零すことなくシャード数の切り替えが行えます。デメリットは一点で、データ同期を一時的に止めるのでリインデックス中は最新のデータを扱えなくなります。*1
上記で説明してきたように、今回のリインデックスはサービスのダウンタイムなしで行えます。しかしながら最新のデータを扱えないままサービスを提供するのはあまり宜しくないため、顧客に事前にメンテナンス時間を通知し、その時間内にシャード数の切り替えを行いました。
データ数が多いのでリインデックスが完了するまでに約 8 時間も掛かりました。お客様にご協力いただいたおかげで refresh_interval を無効にすることができたのでこの時間で収まったことになります。もしも refresh_interval を 100 秒に設定していたら倍の 16 時間は掛かっていたかと思うと恐ろしいです。
まとめ
今回のシステム要件とデータ量の場合、ダウンタイムなしの約 8 時間でリインデックスが完了しました。しかし、近い将来にまた負荷を緩和するためのシャード数の切り替えを行わなければなりません。なぜなら、このリインデックスを行った当時のドキュメント数は約 6,600 万で現在は約 9,300 万弱とありがたいことに利用者は順調に増えているからです。
今回の対応が次回も丸々使えるかと言うと規模が増大しているため使えないと思います。しかし、今回の対応でシャード数切り替えやリインデックスに対する知見は得られたので、今後の Amazon OpenSearch の運用をより良くしていくために模索していきたいと思います。
リインデックスは、リインデックス中のデータ登録/更新/検索が行なえます。しかし、リインデックス中のコピー元のデータ登録/更新はコピー先へ反映されないため、コピー元とコピー先のインデックス内容に差異が生じます。
*1:リインデックスは、リインデックス中のデータ登録/更新/検索が行なえます。しかし、リインデックス中のコピー元のデータ登録/更新はコピー先へ反映されないため、コピー元とコピー先のインデックス内容に差異が生じます。