 RevCommで音声処理の研究開発を担当している加藤集平です。皆さんは電話の通話相手が屋外やカフェなどの雑音環境下にいるために、相手の声が聞こえづらくて苦労した経験はありませんか?本記事では、物理的な音量はそのままに雑音環境下の聞こえ(音声了解度)を改善するモデルであるNELE-GANを用いた、通話相手が雑音環境下にいても聞き取りやすい電話の実現に向けた実験を紹介します。弊社のサービスであるMiiTel(ミーテル)の大量の通話音声を用いてモデルを学習することで、ベースラインよりも大幅に性能を改善することに成功しました。
RevCommで音声処理の研究開発を担当している加藤集平です。皆さんは電話の通話相手が屋外やカフェなどの雑音環境下にいるために、相手の声が聞こえづらくて苦労した経験はありませんか?本記事では、物理的な音量はそのままに雑音環境下の聞こえ(音声了解度)を改善するモデルであるNELE-GANを用いた、通話相手が雑音環境下にいても聞き取りやすい電話の実現に向けた実験を紹介します。弊社のサービスであるMiiTel(ミーテル)の大量の通話音声を用いてモデルを学習することで、ベースラインよりも大幅に性能を改善することに成功しました。
※本記事の内容は、筆者らが日本音響学会2022年春季研究発表会で発表した内容(加藤 & 橋本, 2022)に基づいています。
加藤集平(かとう しゅうへい)
シニアリサーチエンジニア。RevCommには2019年にジョインし、音声処理を中心とした研究開発を担当。ADHDと付き合いつつ業務に取り組む2児の父。
個人ウェブサイト X
→ 過去記事一覧
要約
- NELE-GANを、非常に大量のMiiTel通話音声および様々な雑音の組合せで学習しました(学習データ量はNELE-GANの論文の実験の最大33倍)。
- 上記のデータを用いて学習した結果、音声了解度を同程度に保つかさらに向上させた上で、音声品質を大幅に向上させることに成功しました。
背景
雑音の大きい環境下では、同じ音声でも雑音の小さい環境下にくらべて聞き取りが難しくなります。音声了解度 (speech intelligibility) は音声により伝えられた単語や文章が相手にどれだけ正確に伝わるかを表す尺度で、雑音環境下ではこの音声了解度が下がることが知られています。
音声了解度が下がる仕組みは未だ解明されていません。一方で、音声の周波数特性などを変化させることで音声了解度が向上することがあることが知られています。実は私たち人間は雑音環境下で無意識のうちにこれを行っており、この現象はロンバード効果 (Lombard effect) (Lombard, 1911) と呼ばれています*1。
雑音環境下での音声了解度(つまり音声の聞き手が雑音環境下にある場合の音声了解度)を向上させるように音声を変換する(音声強調を行う)ことは、near-end listening enhancement (NELE) と呼ばれています*2。本記事では2021年に提案されたばかりのNELE-GAN (Li & Yamagishi, 2021) を用いた実験を行います。この手法は、複数の音声了解度の客観評価値を向上させるような変換*3を、敵対的学習ネットワーク (generative adversarial network; GAN) によって学習します。
Li & Yamagishi (2021) では、学習データに男女各1名の英語読み上げ音声(各600文、合計1,200文)を用いています。本記事では、モデルを電話音声により適応させると同時に汎化性能*4をより高めるため、大量のMiiTelの通話音声を用いてモデルを学習し、その性能をベースライン(Li & Yamagishi (2021) の著者らが公開しているモデルと同等のモデル)と比較します。
本手法で強調した音声の例
強調前
強調後
ランダムな数字を読み上げている音声に、雑音を付加したものです。強調前と強調後でSNR*5は同じにしてありますが、強調後の音声のほうがより聞き取りやすくなっていることが分かります。
手法
NELE-GANの詳細についてはLi & Yamagishi (2021) に譲りますが、モデルの構造は図1および図2のようになっています。
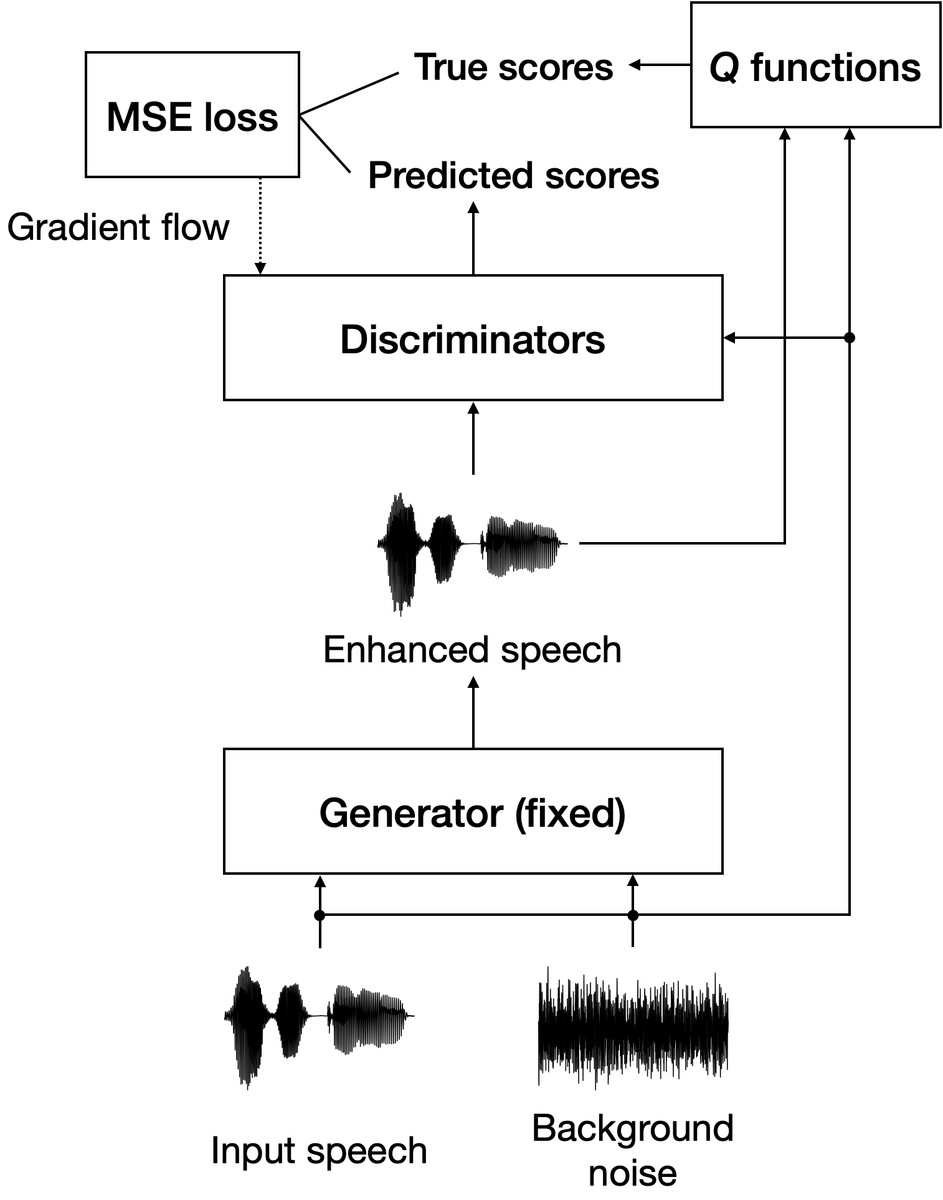
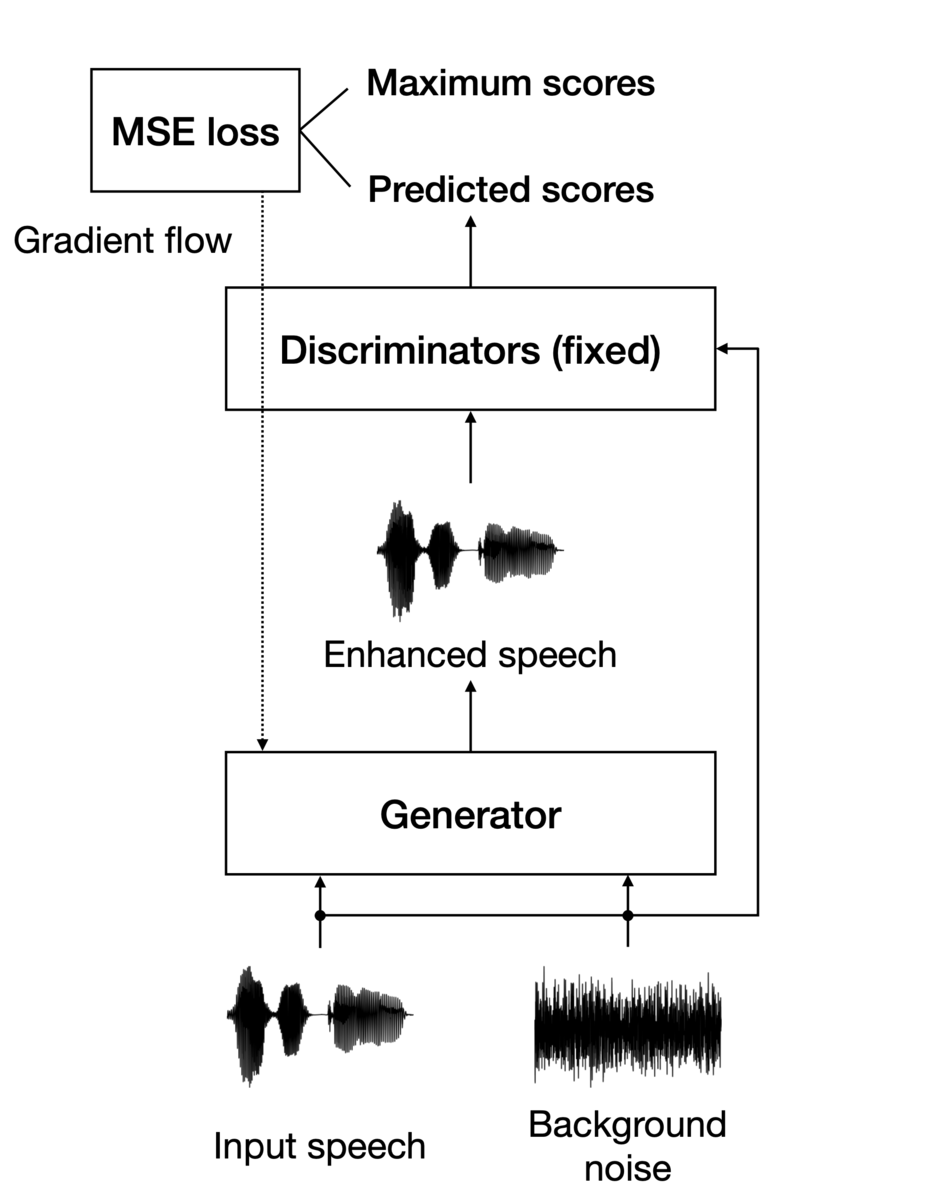
NELE-GANは、クリーンな音声(背景雑音をほとんど含まない音声)および雑音を入力とし、識別器からは客観指標の推定値が出力され、生成器からは音声の周波数特性を変化させるフィルタが生成されます。
識別器の学習においては、Q関数(複数の客観評価値を算出する関数)の出力である客観指標の真の値と、識別器が出力する客観指標の推定値の平均二乗誤差損失 (mean squared error loss; MSE loss) を最小化するように学習が行われます。一方、生成器の学習においては、客観指標の取りうる最大値と、識別器が出力する客観指標の推定値のMSE lossを最小化するように学習が行われます(このとき、識別器の重みは固定します)。これらを交互に繰り返すことで、客観評価値を最大化するようなフィルタを学習することができます。
Q関数では、音声了解度を表す3つの客観指標に加えて、音声品質を担保するための2つの客観指標が用いられます。
音声了解度を表す客観指標
- Speech intelligibility in bits (SIIB) (Kuyk et al., 2018)
- Hearing-aid speech perception index (HASPI) (Kates & Arehart, 2014)
- Extended short-time objective intelligibility (ESTOI) (Jensen & Taal, 2016)
音声品質を表す客観指標
- Perceptual evaluation of speech quality (PESQ) (Rix et al., 2001)
- Virtual speech quality objective listener (ViSQOL) (Hines et al., 2015)
実験
音声データおよび雑音データ
音声データには、弊社の業務においてMiiTelを通じて行われた通話音声から、弊社から発信した通話を着信した側のチャンネルの音声区間のみを抜き出して使用しました。着信側の話者がそれほど重複しているとは考えづらいので、話者数は通話件数とほぼ等しいと見なせます。なお、音声は厳密な意味でのクリーンな音声ではありませんが、この実験のためにできる限りクリーンな音声を選別しました。
音声データについては、モデルの学習・検証のために、S: 音声区間数2,269(通話件数466件、4.2時間)、M: 音声区間数9,004(通話件数2,089件、16.7時間)、L: 音声区間数34,962(通話件数7,322件、66.7時間)の3つのデータセットを用意しました。ただし、音声区間数のより多いデータセットは、より少ないデータセットを包含しています。モデルの評価のためには、学習・検証のために使用していない音声区間数116(通話件数18件、0.56時間)のデータセットを用意しました。
雑音データには、Li & Yamagishi (2021) と同じく、The Microsoft Scalable Noisy Speech Dataset (MS-SNSD) (Reddy, 2019) を使用しました。モデルの学習・検証のために、a: 音声系の雑音3種類 (airport, babble, neighbor speaking)、b: セットa(音声系の雑音3種類)+雑踏系の雑音2種類 (traffic, station) の2つのセットを用意し,それぞれ SNR = −10 dB, −5 dB, 0 dB となるように雑音を音声に重畳しました。モデルの評価のためには、closed: 学習・検証セットaと同一種類の雑音(音声系の雑音3種類、ただし異なるサンプルです)、acoust: 学習・検証セットaに含まれるものとは異なる音声系の雑音2種類 (bus, cafe)、crowd: 学習・検証セットbに含まれるものとは異なる雑踏系の雑音2種類 (field, metro)、office: オフィス系の雑音3種類 (air conditioner, copy machine, typing) の4つのデータセットを用意し、それぞれ SNR = −12 dB, −9 dB, −6 dB, −3 dB, 0 dB, +3 dB となるように雑音を音声に重畳しました。
結果として、モデルの学習・検証にはSa–Lbの6つのデータセット、評価には4つのデータセットを用いました(表1、2)。Saがベースライン(Li & Yamagishi (2021) の著者らが公開しているモデル)に最も近いモデルになります。なお、学習・検証に用いたSa–Lbの6つのデータセットについては、無作為に選んだ320サンプルを検証に、残りのサンプルを学習に用いました*6。
| データセット | 音声データセット | 雑音データセット | SNR | サンプル数 | 時間長 [h] |
|---|---|---|---|---|---|
| Li & Yamagishi (2021) | 1,320サンプル(時間長不明) | (4種類) | (3種類) | 15,840 | (不明) |
| Sa | S(4.2時間) | a(3種類) | -10 dB, -5 dB, 0 dB(3種類) | 20,421 | 37.5 |
| Sb | b(5種類) | 34,035 | 62.5 | ||
| Ma | M(16.7時間) | a | 81,036 | 150 | |
| Mb | b | 135,060 | 250 | ||
| La | L(66.7時間) | a | 314,658 | 600 | |
| Lb | b | 524,430 | 1,000 |
| データセット | 音声データセット | 雑音データセット | SNR | サンプル数 | 時間長 [h] |
|---|---|---|---|---|---|
| Tclosed | (0.56時間) | closed(3種類) | -12 dB, -9 dB, -6 dB, -3 dB, 0 dB, +3 dB(6種類) | 2,088 | 10 |
| Tacoust | acoust(2種類) | 1,392 | 6.7 | ||
| Tcrowd | crowd(2種類) | 1,392 | 6.7 | ||
| Toffice | office(3種類) | 2,088 | 10 |
モデルの学習条件および実験条件
音声および雑音の標本化周波数は8 kHz*7とし、ミニバッチの大きさは32としました。さらに、学習の安定化と高速化のために、1エポック目はSIIB, ESTOI, PESQの3つの指標のみを用いて学習を行い、2エポック目以降は5つ全ての指標を用いて学習を行う方法を取りました。そして、3エポック目以降の学習では、当該エポックの学習を終えた時点での検証セットに対する客観評価値が、前エポック終了時のものよりも小さくなるか上昇率が1 %以下になった時点で学習を打ち切り、客観評価値の平均が最も大きなモデルを評価に使用しました。
モデルの評価においては、評価セットの各サンプルに対する客観評価値を平均したものを、当該セットに対する客観評価値としました。
実験結果
実験結果を図3に示します。 どの評価セット (Tclosed, Tacoust, Tcrowd, Toffice) においても、強調後の音声 (Sa–Lb) は強調前の音声 (unmodified) に対して、音声了解度を表す客観指標 (SIIB, HASPI, ESTOI) の値は上昇傾向にあり,音声品質を表す客観指標 (PESQ, ViSQOL) の値は低下していることが分かります。
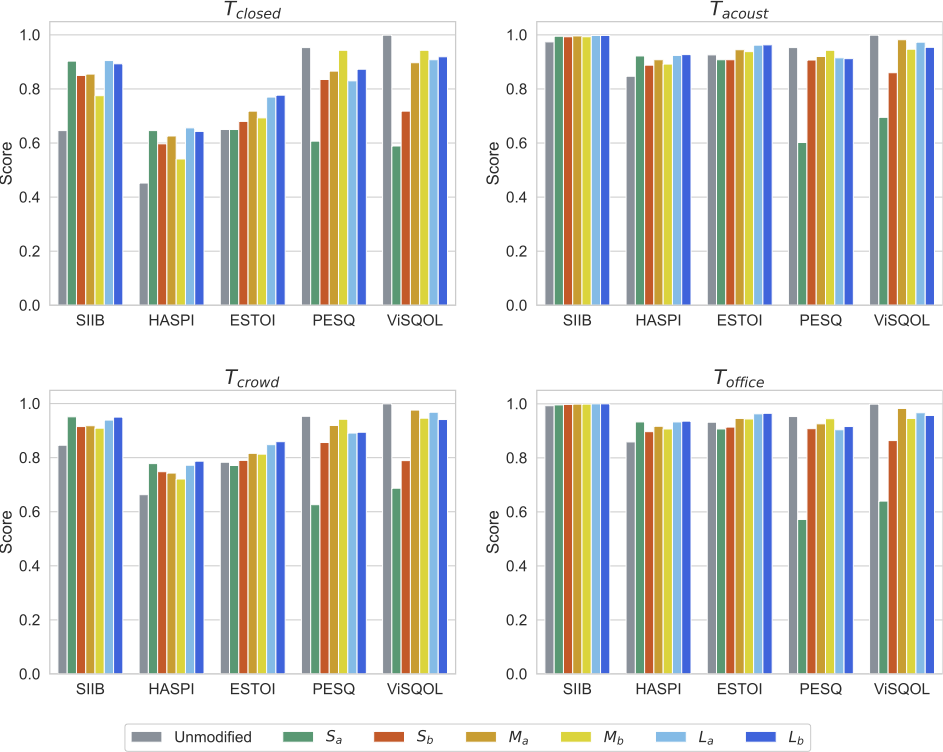
評価セット間の客観評価値の相関を見てみます(表3–5)。音声了解度を表す客観指標 (SIIB, HASPI, ESTOI)、音声品質を表す客観指標 (PESQ, ViSQOL) ごとに見れば、評価セット間の客観評価値の相関係数はおおむね0.9以上と、非常に強い相関があることが分かります。
| Tacoust | Tcrowd | Toffice | |
|---|---|---|---|
| Tclosed | 0.569 | 0.511 | 0.946 |
| Tacoust | - | 0.994 | 0.769 |
| Tcrowd | - | - | 0.720 |
| Tacoust | Tcrowd | Toffice | |
|---|---|---|---|
| Tclosed | 0.929 | 0.891 | 0.969 |
| Tacoust | - | 0.994 | 0.977 |
| Tcrowd | - | - | 0.959 |
| Tacoust | Tcrowd | Toffice | |
|---|---|---|---|
| Tclosed | 0.931 | 0.932 | 0.968 |
| Tacoust | - | 0.997 | 0.978 |
| Tcrowd | - | - | 0.970 |
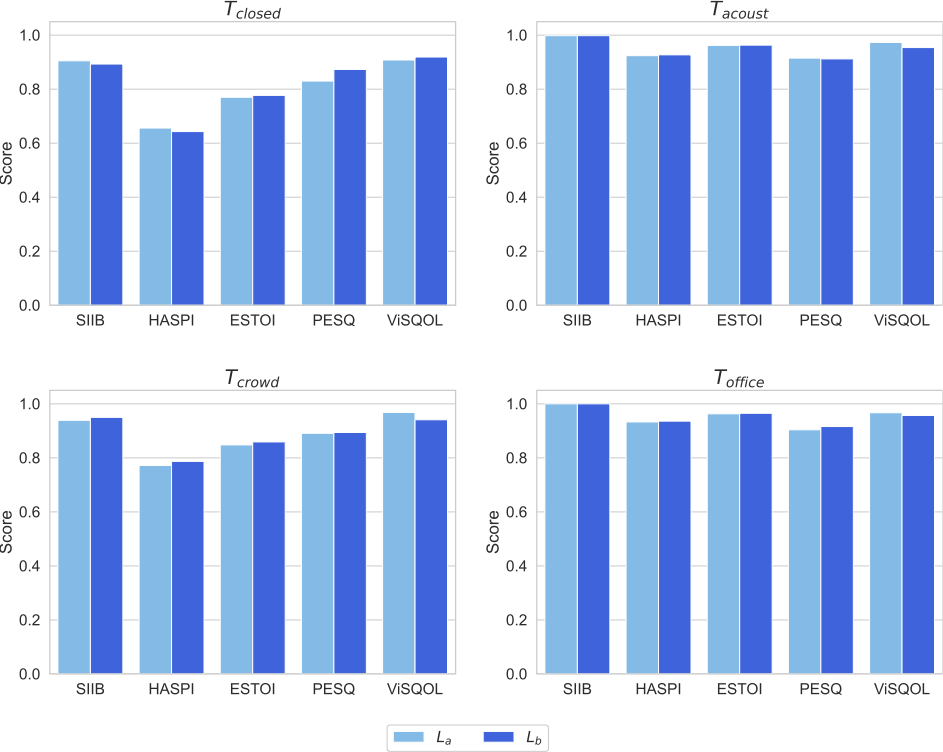
モデルの学習に用いる音声データの量および多様性の変化に伴う客観評価値の変化
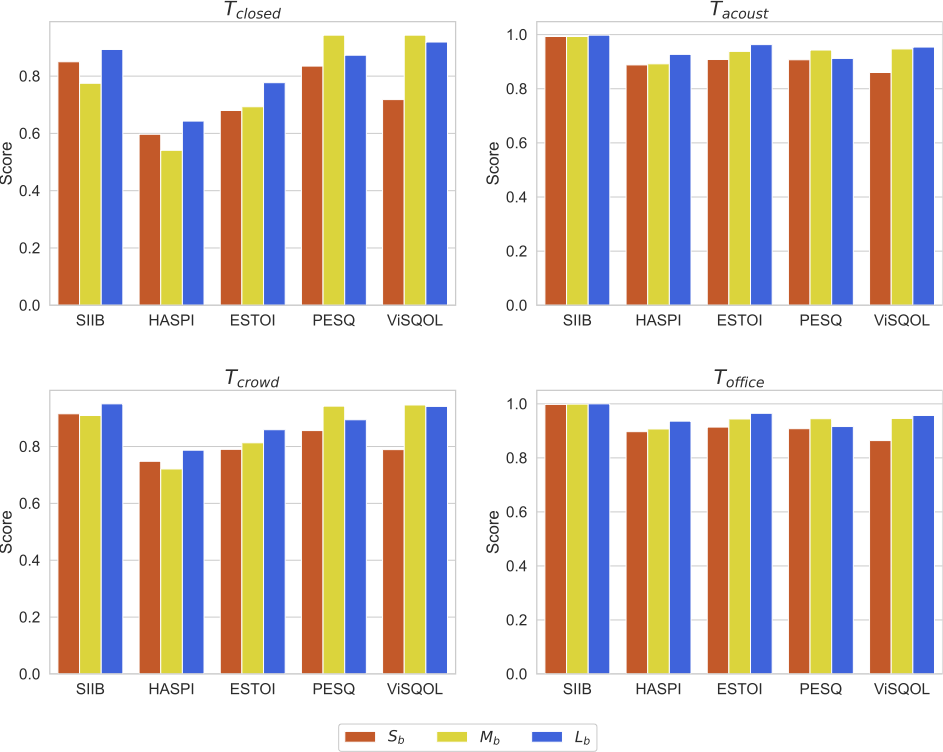
モデルの学習に用いる音声データの量および多様性を変化させると、客観評価値はどのように変化するのでしょうか?これを観察するために、各評価セットに対する結果を (Sa, Ma, La) または (Sb, Mb, Lb) の組合せで比較しました(図4、図5)。音声了解度を表す客観指標のうちSIIBおよびHASPIについては、 Sa/SbからMa/Mbへと音声データの量および多様性を大きくすると値が若干低下しましたが、La/Lbへとさらに大きくすると値は同程度まで回復しました。ESTOIについては、音声データの量および多様性を大きくするにしたがって、単調に値が上昇しました。一方、音声品質を表す客観指標 (PESQ, ViSQOL) については、Sa/SbからMa/Mbへと音声データの量および多様性を大きくすると値が上昇し、La/Lbへとさらに大きくすると値は若干低下するか同程度となりました。

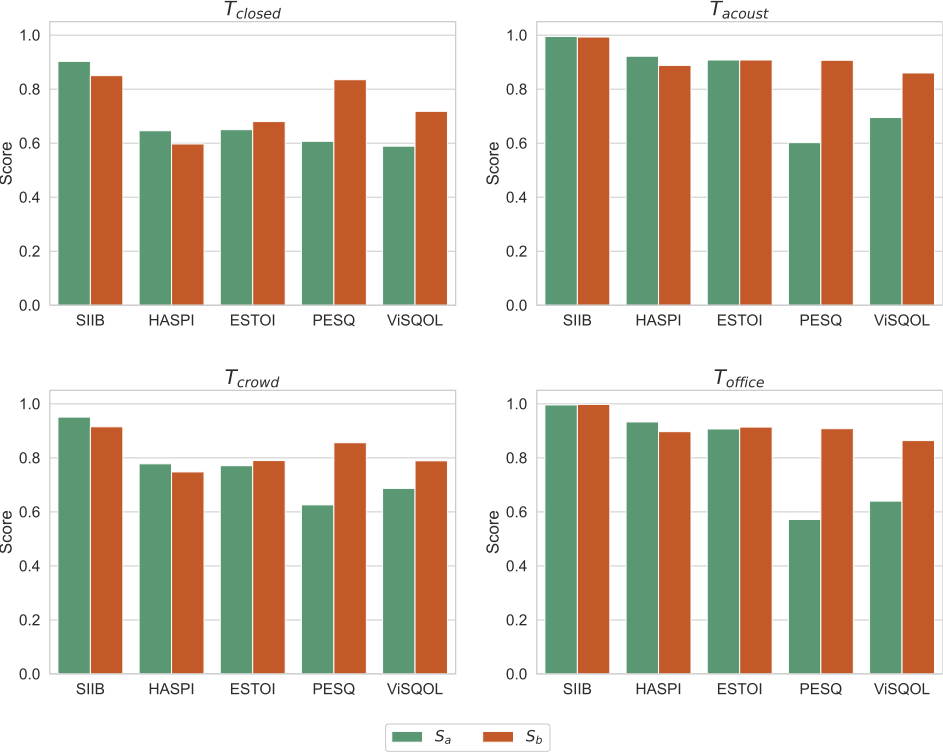
モデルの学習に用いる雑音の多様性の変化に伴う客観評価値の変化
モデルの学習に用いる雑音の多様性を変化させたときの客観評価値の変化についてはどうでしょうか?これを観察するために、各評価セットに対する結果を (Sa, Sb),(Ma, Mb)、または (La, Lb) の組合せで比較しました(図6–8)。音声了解度を表す客観指標 (SIIB, HASPI, ESTOI) については、Sa/MaからSb/Mbへと雑音をより多様にすると若干値が低下しましたが、LaからLbへの変化については、値が同程度か若干の上昇にとどまりました。音声品質を表す客観指標 (PESQ, ViSQOL) については、SaからSbへと雑音をより多様にすると値が大きく上昇しましたが、Ma/LaからMb/Lbへと変化させた場合は、評価セットや客観指標によるものの、値はおおむね同程度にとどまりました。

考察
汎化性能
評価セット間の客観評価値には、非常に強い相関が見られました。これは、音声データの量および多様性、雑音の多様性の変化によらず、異なる系統の雑音に対するモデルの性能変化の傾向が類似していることを示しています。雑音種類オープンの評価セット (Tacoust, Tcrowd, Toffice) に対する客観評価値が雑音種類クローズド (Tclosed) の評価セットに対する客観評価値を上回ったことをあわせて考えると、NELE-GANが雑音の種類に対して高い汎化性能を持っていることが示唆されます。
音声データの量および多様性を変化させたときの音声了解度や音声品質の変化
音声データの量および多様性を変化させたときの音声了解度や音声品質の変化については、興味深い傾向が見られました。すなわち、比較的小規模の音声データを用いて学習した場合 (Sa/Sb) でも音声了解度は十分に向上しましたが、音声品質は大きく劣化してしまいました。そこからデータの規模を大きくすると、一旦は音声了解度が若干低下する一方で、音声品質はかなり回復しました (Ma/Mb)。さらにデータの規模を大きくすると、音声品質をおおむね保ちつつ、音声了解度が回復またはさらに向上することが分かりました (La/Lb)。このことから、非常に大量かつ多様な音声データを用いてNELE-GANを学習することで、比較的少量のデータを用いて学習する場合よりも、モデルの性能を向上させることができると言えるでしょう。
雑音の多様性を変化させたときの音声了解度や音声品質の変化
雑音の多様性を変化させたときの音声了解度や音声品質の変化は、音声データが比較的小規模の場合は顕著に差がありましたが、より大規模であるほど差は少なくなりました。この理由については、本実験の結果からだけでは推測が難しく、さらなる検討を必要とします。
結論
本記事では、NELE-GANをより大量かつ多様な音声データを用いて学習したときのモデル性能の変化を検証しました。同時に、音声に重畳する雑音についても、その多様性を変化させたときのモデル性能の変化を検証しました。結果として、非常に大量かつ多様な音声データを用いることで、比較的少量のデータを用いる場合とくらべて、音声了解度を同程度に保つかさらに向上させた上で、音声品質を大幅に向上させられることが明らかになりました。
さらに大規模な音声データを用いた場合のモデル性能がどうなるのか気になりますが、それは今後の課題とします。
発表文献
加藤集平, & 橋本泰一 (2022). NELE-GANの学習に用いる音声データ量および多様性の影響についての調査. 日本音響学会2022年春季研究発表会講演論文集, 1025–1028.
参考文献
Glasberg, B. R., & Moore, B. C. J. (1990). Derivation of auditory filter shapes from notched-noise data. Hearing Research, 47(1–2), 103–138. https://doi.org/10.1016/0378-5955(90)90170-T
Hines, A., Skoglund, J., Kokaram, A. C., & Harte, N. (2015). ViSQOL: An Objective Speech Quality Model. EURASIP Journal on Audio, Speech, and Music Processing, 2015(13), 1–18.
Jensen, J., & Taal, C. H. (2016). An Algorithm for Predicting the Intelligibility of Speech Masked by Modulated Noise Maskers. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 24(11), 2009–2022. https://doi.org/10.1109/TASLP.2016.2585878
Kates, J. M., & Arehart, K. H. (2014). The Hearing-Aid Speech Perception Index (HASPI). Speech Communication, 65, 75–93. https://doi.org/10.1016/j.specom.2014.06.002
Kuyk, S., Kleijin, W. B., & Hendriks, R. C. (2018). An Instrumental Intelligibility Metric Based on Information Theory. IEEE Signal Processing Letters, 25(1), 115–119. https://doi.org/10.1109/LSP.2017.2774250
Li, H., & Yamagishi, J. (2021). Multi-Metric Optimization using Generative Adversarial Networks for Near-End Speech Intelligibility Enhancement. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29, 3000–3011. https://doi.org/10.1109/TASLP.2021.3111566
Lombard, É. (1911). Le signe de l'élévation de la voix. Annales des Maladies de L'Oreille et du Larynx, XXXVII(2), 101–109.
Reddy, C. K. A., Beyrami, E., Pool, J., Cutler, R., Srinivasan, S., & Gehrke, J. (2019). A Scalable Noisy Speech Dataset and Online Subjective Test Framework. Proc. INTERSPEECH, 1816–1820. https://doi.org/10.21437/Interspeech.2019-3087
Rix, A. W., Beerends, J. G., Hollier, M. P., & Hekstra, A. P. (2001). Perceptual Evaluation of Speech Quality (PESQ) — A New Method for Speech Quality Assessment of Telephone Networks and Codecs. Proc. IEEE International Conference on Acoustic, Speech, and Signal Processing (ICASSP), II, 749–752. https://doi.org/10.1109/ICASSP.2001.941023
芝慎太朗, 橘亮輔, & 岡ノ谷一夫 (2015). ジュウシマツの歌発声におけるロンバード効果と基本周波数の変化. 情報処理学会研究報告, 2015-MUS-107(37), 1–3.
*1:もっと言えば、人間以外の動物でもロンバード効果が観察されることがあることが知られています(芝慎太朗ほか, 2015)。
*2:音声強調という言葉は、雑音や残響が混ざった音声信号においてそれらを抑制することを指すことが多いです。
*3:具体的には、あらかじめビン数を固定したequivalent rectangular bands (ERB) (Glasberg & Moore, 1990) 尺度に基づくフィルタバンクの各ビンに対する重み付けを行います。
*4:モデルが特定の場面に限らず広い場面で高い性能を発揮すること。ここでは、どのような声あるいはしゃべり方の人でも聞き取りやすい声に変換できることを指しています。
*5:Signal to noise ratio(S/N比、信号対雑音比)。信号(ここでは音声信号)のパワーの雑音のパワーに対する比で、値が小さいほど雑音が大きいことになります。
*6:音声データの学習・検証セットSに雑音データの学習・検証 セット(aまたはb)を重畳したものを、雑音の種類、音声サンプル(ランダムな識別子を付与)の順にソートして並べ、前半の320サンプルをS/M/L共通の検証セットとしました。
*7:Li & Yamagishi (2021) では16 kHzでしたが、本実験に用いた音声は電話の通話音声であるため、標本化周波数は電話の音声信号を符号化する際に用いられる8 kHzに制限されます。