
はじめに
この記事は RevComm Advent Calendar 2023 の 19 日目の記事です。
こんにちは @sara_ohtani_mt2です。 バックエンド開発をしています。
最近は、いわゆる電話帳のような連絡先を管理する機能のリニューアルに取り組んでいます。 これは現在、処理速度やシステムの拡張性の向上が求められている機能で、その改善を図るためのリニューアルプロジェクトです。 大きなモノリスだったところから機能を切り出して、新しい基盤構築から行っています。 今後他機能にも知見を展開できるよう、様々な選択肢を検討しながら技術の選定を進めています。
改善にあたり、ポイントの1つとなっているのがDB選定・設計です。 弊社サービスの MiiTel はマルチテナント型サービスであり、テナントごとの連絡先データ数が数十万件にも及ぶ規模のものもあります。 クエリレスポンスのスピードの向上を目指す中で、今回AuroraからDynamoDBへの載せ替えを検討しました。 残念ながら結果的には部分一致検索の実用性の点で課題を感じたため、現時点ではDynamoDBの利用を見送ることになりました。 しかし「前方一致で良い」など特定のユースケースにおいては有望だと感じたので、テーブル設計例と合わせてご紹介したいと思います。
DynamoDBが夢に出るようになってきた
— sara.ohtani.mt2 (@sara_ohtani_mt2) 2023年8月13日
DynamoDBがマッチすると思われるユースケース
DynamoDBの基本的なユースケースについては最新の公式ドキュメント*1を参照してください。 マッチすると思われる条件のうち、今回特に注目する点です。
- データ抽出条件が完全一致、あるいは前方一致で良い
- データ件数が多く、今後もさらに増加が予想される
- アクセスパターンや要件がはっきりしている
- データ検索する際の絞り込み条件となる項目が多くない
- 基本的にテーブルをjoinする必要がない
- 並び順は問わない
DynamoDBベストプラクティスと設計する上での注意事項
ベストプラクティス
公式ベストプラクティス*2 から今回特に意識したことを抜粋します。
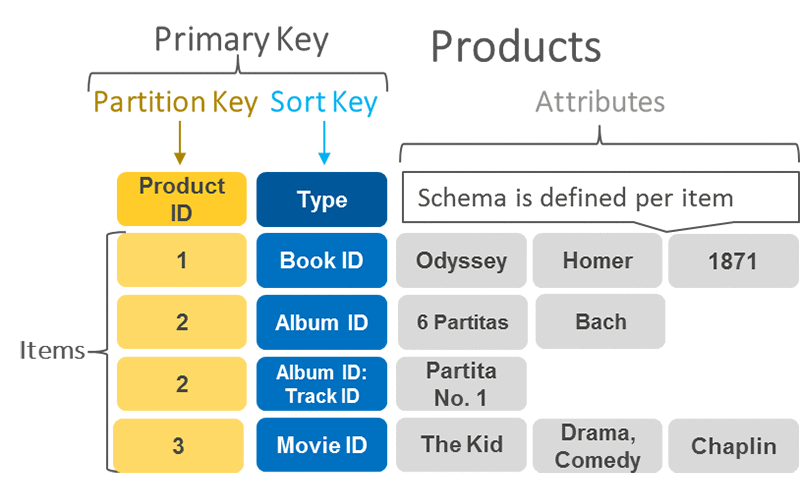
- GSIの数を抑える
- GSIは基本となるテーブルを同期している別テーブルみたいなものなので増やすと書き込みコストがその分増えてしまう
- RDBならテーブル分割するようなものも全て1つのテーブルで表現する
- キャパシティを効率的に使うため
- そもそも1 アカウントあたりのテーブル数は 10,000 が上限
- つまりテーブルあたりのデータ量の多さが悩みだからといってどんどん分割してテーブルを増やしていくような設計は合わない
- 特定のデータ範囲に対してアクセスが集中するようなホットパーテーションが発生しないようにする
- いかにホットパーテーションを生まないかが設計のポイントの1つ
- 1処理内のアクセスだけでなく、パラレルでの処理でそれぞれのアクセスがパーテーションに集中してもホットになる
- オンデマンドキャパシティーモードでも、例えば数千万件を一気に書き込もうとすると
Throughput exceeds the current capacity of your table or indexというエラーが出て、調べていくとホットパーテーションが問題だとわかったことがあった
- 1回のクエリで取得できるサイズ上限が1MBであることに注意
- 1回で取得できなかったときにはLastEvaluatedKeyに値が入ってくる
- クエリで取得するitemの1itemごとのサイズに大きなばらつきがあると1回のクエリで取得できるデータ件数が変わってわかりづらい
部分一致検索をしたいと思ったときの注意事項
- Scan検索は部分一致検索が可能だが、全体のデータ数が多いと遅い
- keyとattributeはQueryで扱う上で全く別物といっていい
- Queryでの検索の場合、絞り込み条件としてkeyは必ず指定しなければならない
- Query検索にもcontainsという部分一致検索できるものはあるがScan同様データが多いと遅い
- さらにattributeに対してしか使えない、keyに対しては使えない
テーブル設計の例
サンプル要件
連絡先リニューアルプロジェクトの要件をもとにしたブログ説明用の架空のサンプル要件です。 DynamoDBの仕様に合うようにアレンジを加えているため、実際の弊社サービスの連絡先機能とは異なります。
機能概要
マルチテナントサービスで、テナント内で共有する顧客の連絡先を管理する電話帳のような機能
アクセスパターンと要件
連絡先情報を一覧で表示する画面があり、キーワード検索する機能がある
- contact_idで紐づく他データと合わせて表示する
- 初期表示時はテナント内の全連絡先を表示
- 連絡先の情報(名前、会社名、電話番号)とカテゴリ名の前方一致検索をしたい
- 画面に出す100件ずつ取れれば良い
- データ作成日順で表示したい
余談ですが、アクセスパターンを整理するのが大事ということなので整理の手法には RDRA*3を使ってみました。
その他要件
- 1テナントにつき連絡先が最大50万件扱えるようにしたい
- テナントごとに管理している項目としてカテゴリがあり、連絡先とは多対多の関係
テーブル定義
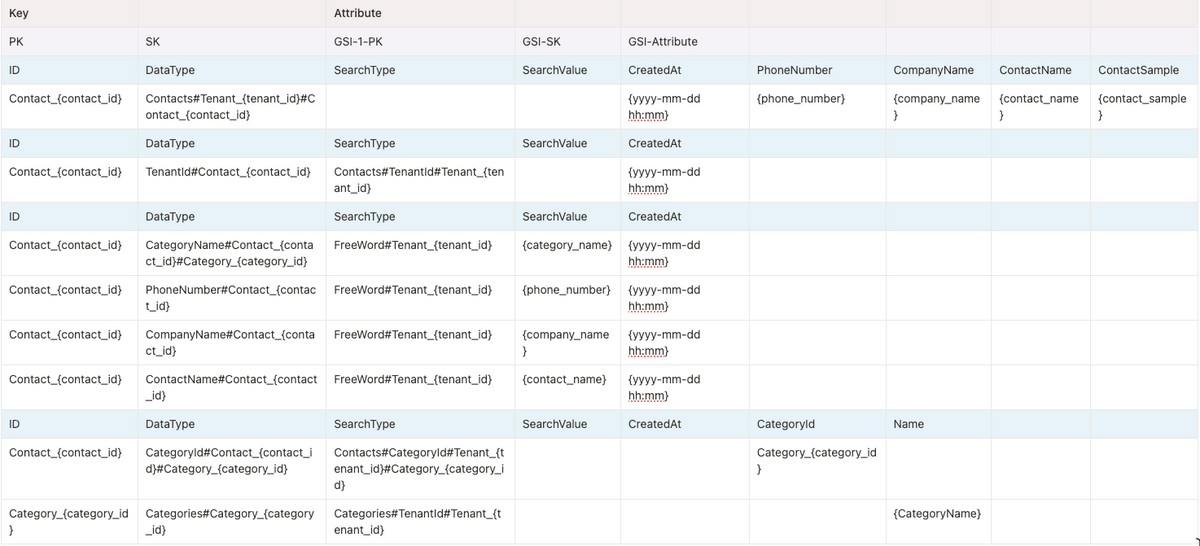
Attributeがデータの種類ごとに変わるのでそれぞれに見出しを書いているが全て1テーブル内に格納するデータです。
{}には該当する値がセットされる想定です。
(例: Contact_{contact_id} → Contact_064d0d85-9d74-7f2f-8000-644443c7c8dc)
テーブルとGSI
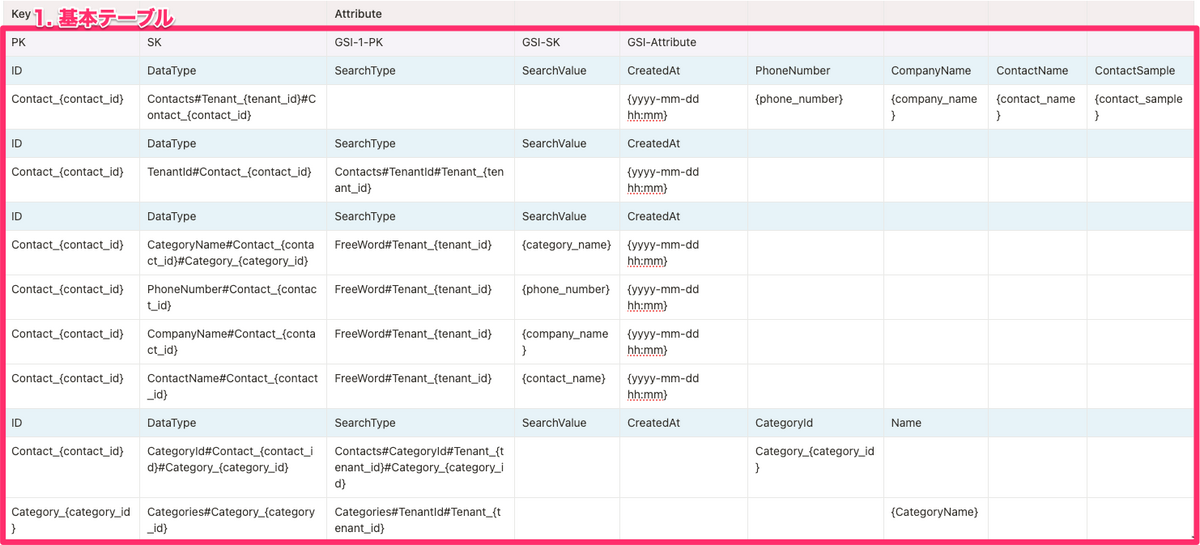
1. 基本テーブル
データを重複なく保管し、ホットパーテーションが発生しないようにするためのPK, SKを設定します。
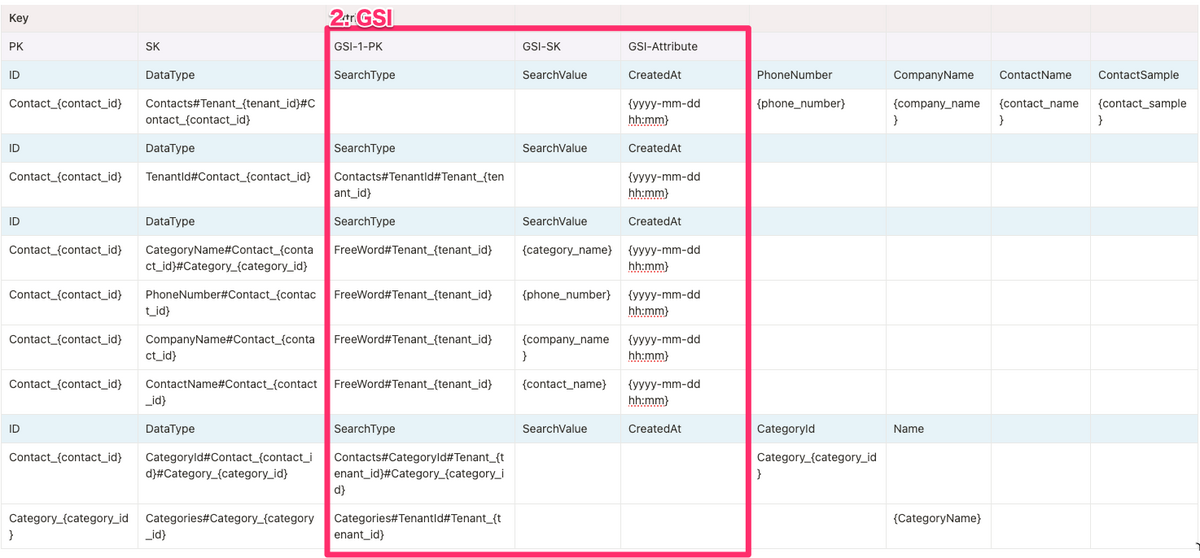
2. GSI
GSIは検索のためのものを1つだけ作成しています。 検索のためのPK, SKをGSI用に設定しています。 GSIでは全カラムをもつ必要がないので検索とソートに必要な項目だけ基本テーブルから射影します。
データの種類の定義と種類ごとの各項目の値の意味
データの種類の名称はブログ説明するためのもので公式な呼び方ではありません。
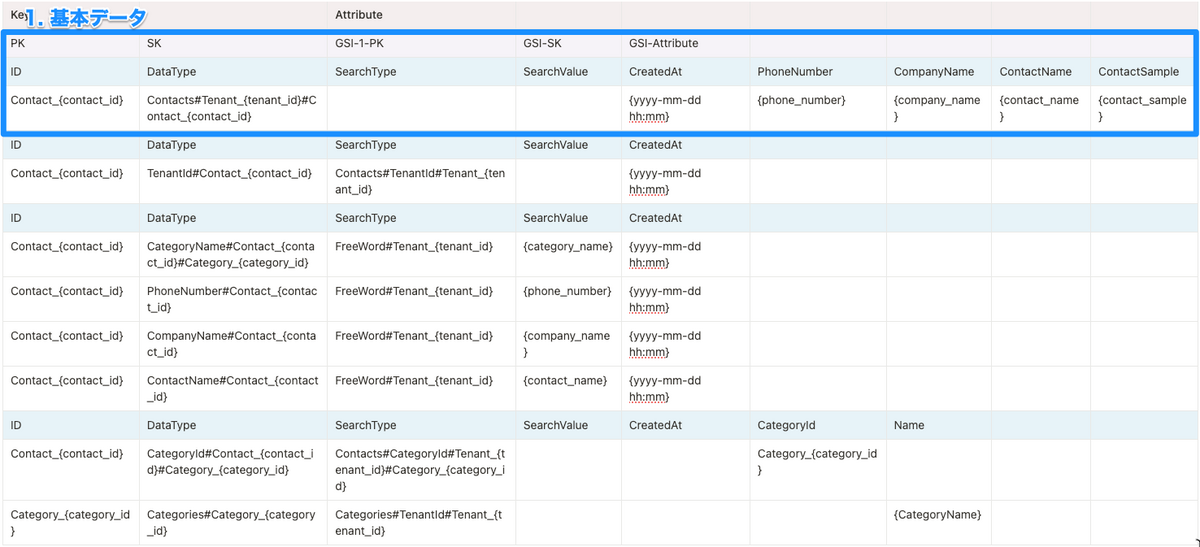
1. 基本データ
IDを絞り込んだ結果、取って来たいデータです。
- DataType:
なんのデータ#どのテナントと紐づいてるか#どの連絡先と紐づいてるか- DataTypeはいずれも基本的にデータ重複ないように保持するためのものとしている
- ここのconact_idはアプリケーション上必要な情報ではないが、ホットパーテーション回避するために入れている
- tenant_idはあってもなくてもいいのですが、ConactsのItemの情報としてどのテナントのデータかあった方があとで調査とかしやすそうなので置いてみている
- 各idに
Contact_〜などの見出しをつけるのは、見やすさ向上のためと、全てのデータが1つのテーブルに入っているため他項目間のidの重複を避けるため - call_sampleのようにcontact_idと紐付けられるデータは、できれば1itemに入れてしまったほうがクエリが楽になる
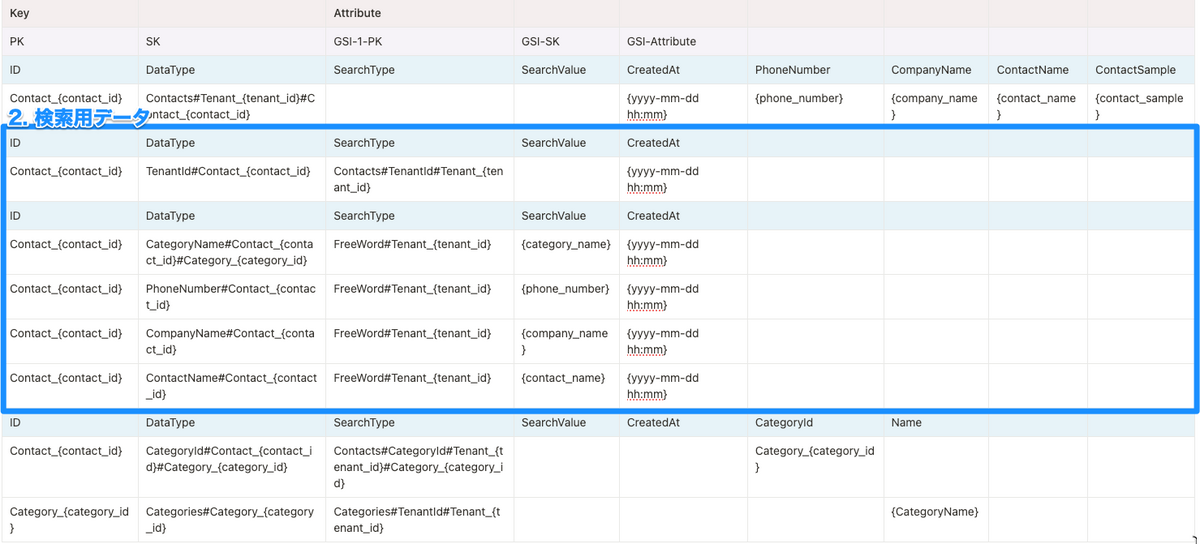
2. 検索用データ
- DataType:
なんのデータ#どの連絡先と紐づいてるか- カテゴリの場合は複数紐づくのでさらにcategory_idも
- SearchType:
検索の種類#テナントid - SearchValue:
"なんのデータ"の値 - CreatedAt(アプリケーションとしてのソートしたい項目): id取得のための検索itemと基本情報itemにだけセットすればいい
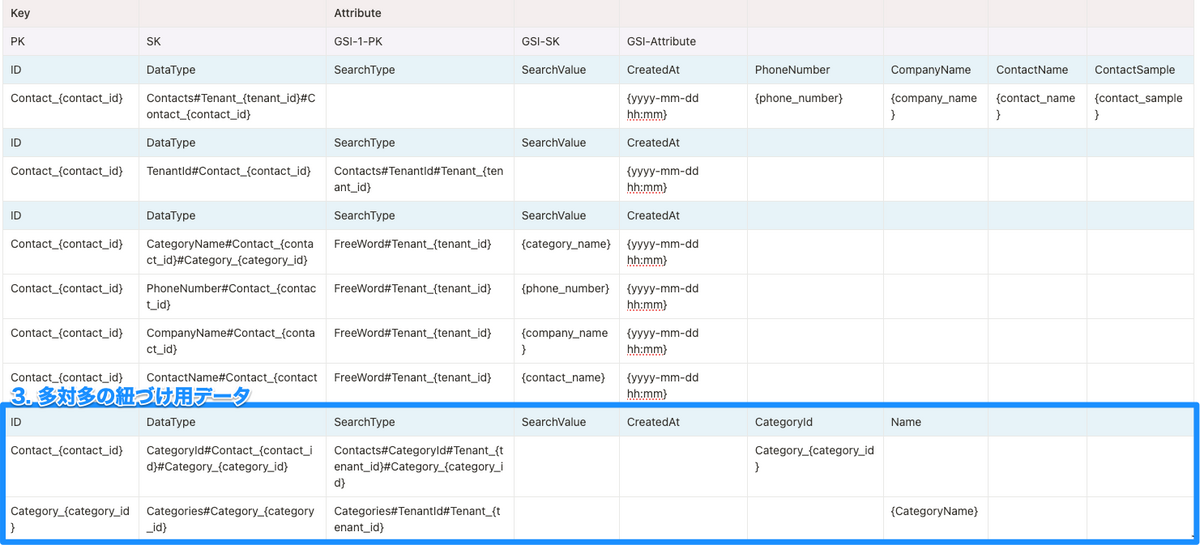
3. 多対多の紐づけ用データ
- DataType:
なんのデータ#どの連絡先と紐づいてるか#紐づくデータ - SearchType:
検索の種類#どのデータと紐付けるか(ON的な)#紐付ける値
多対多のデータの考え方については最後に記載した参考ブログがわかりやすくておすすめです。
データ取得イメージ
連絡先一覧画面でキーワード検索したときのデータ取得の流れのイメージです。
- GSI経由で検索用データから条件に一致するcontact_id一覧を取得する
- 取得したcontact_id一覧から基本データを取得する
動作確認環境: AWS Lambda ランタイム Python 3.11
import boto3 def main( dynamodb_client, table_name, index_name, partition_key, sort_key, gsi_partition_key, gsi_sort_key, tenant_id, app_sort_key, keyword ): items = [] exclusiveStartKey = "" # クエリパラメータの設定 params = { "TableName": table_name, "IndexName": index_name, "KeyConditionExpression": f"#pk = :pkval and begins_with(#sk, :skval)", "ExpressionAttributeNames": { "#pk": gsi_partition_key, "#sk": gsi_sort_key, }, "ExpressionAttributeValues": { ":pkval": {"S": "FreeWord#"+tenant_id}, ":skval": {"S": keyword}, } } # できるだけ少ない回数で取得できるようにGSIの項目は少なくしたい while True: if exclusiveStartKey: params["ExclusiveStartKey"] = exclusiveStartKey print("exclusiveStartKey: ", exclusiveStartKey) response = dynamodb_client.query(**params) items.extend(response["Items"]) if "LastEvaluatedKey" not in response: break exclusiveStartKey = response["LastEvaluatedKey"] # 重複を取り除くために一時的なセットを使用 temp_set = set() filtered_items = [item for item in items if item[partition_key["name"]][partition_key["type"]] not in temp_set and not temp_set.add(item[partition_key["name"]][partition_key["type"]])] # 先頭100件を取得するために並び替え sorted_items = sorted(filtered_items, key=lambda x: x[app_sort_key["name"]][app_sort_key["type"]], reverse=True) contact_list = [item[partition_key["name"]][partition_key["type"]] for item in sorted_items] if not contact_list: return chunk_size = 100 items_par_page = 100 page = 1 first_element = (page - 1) * items_par_page # ページネーション chunk = contact_list[first_element:first_element+chunk_size] # SQLのinのような絞り込み条件を設定したい場合は batch_get_item() を使う contacts = batch_get_item(dynamodb_client, table_name, {table_name: {"Keys": [{partition_key["name"]: {partition_key["type"]: contact_id}, sort_key["name"]: {sort_key["type"]: "Contacts#"+tenant_id+"#"+contact_id}} for contact_id in chunk]}}) # アプリケーションの表示順にするために並び替え contacts = sorted(contacts, key=lambda x: x[app_sort_key["name"]][app_sort_key["type"]], reverse=True) return { "contacts": contacts } def batch_get_item(dynamodb_client, table_name, request_items): max_retry = 100 results = [] for _ in range(max_retry): batch_get_item_response = dynamodb_client.batch_get_item(RequestItems=request_items) results.extend(batch_get_item_response["Responses"].get(table_name, [])) unprocessed_key = batch_get_item_response["UnprocessedKeys"] if unprocessed_key: request_items = unprocessed_key else: break return results def lambda_handler(event, context): dynamodb_client = boto3.client("dynamodb") return main( dynamodb_client, table_name="sample-table", index_name="SearchType-SearchValue-index", partition_key={"name": "ID", "type": "S"}, sort_key={"name": "DataType", "type": "S"}, gsi_partition_key="SearchType", gsi_sort_key="SearchValue", tenant_id="Tenant_uuid1", app_sort_key={"name": "CreatedAt", "type": "S"}, keyword="0" )
結論
条件ふりかえり
データ抽出条件が完全一致、あるいは前方一致で良い → 実際のプロジェクトの技術選定で今回DynamoDBを採用しなかった一番の理由が、部分一致だと大量データの検索がスピーディにできないことでした。 完全一致、あるいは前方一致で良いものにはぜひ採用を検討したいです。
データ件数が多く、今後もさらに増加が予想される → データ数が多くてもユースケースがマッチしていて設計がうまくいけばかなり速いです。
アクセスパターンや要件がはっきりしている → ホットパーテーションが生まれないようになど事前の設計がかなり大事です。 アクセスパターンが決まっていない状態でこのような検索の仕組みにするのはおすすめできません。
データ検索する際の絞り込み条件となる項目が多くない → 今回のような設計にすると項目が多ければ多いほど1件の連絡先あたりのitem数が増えることになり、書き込み・読み込み時のコストも増えていくことになります。
基本的にテーブルをjoinする必要がない → これもjoinするテーブルが多いほど1件の連絡先あたりのitem数が増えることになります。 全体のクエリも複雑になるのでできればない方がいいです。
並び順は問わない → SQLでいうところのorder byがないのでソートキー順以外の並び順にしたいときは一度全検索結果のidと並び順条件の情報を取得した上でアプリ側でソートしていました。 そうすると本当は100件のデータ取得でいいところが全結果を取得しないといけなくなるので並び順は選べないと思っていたほうが効率が良さそうです。
その他おまけ
- むちゃしてQueryの前方一致検索を使いながら任意のキーワードのHit対象を増やそうとするとなんか最終的に自分で全文検索のための数文字おきに区切ったデータ作るみたいなことになっちゃう
- 例えば会社名で検索したときに「株式会社」などは入力しないでもHitするようにSearchValueから取り除いたデータも作るなど
- やたら分割するとデータ量が爆発的に増えていくのでコストもかかる
- RDBでは考えないようなことを色々やることになる
- 基本となるデータに変更があった場合にStreamなどで関連レコードを更新する必要がある
- emailなど今後連絡先で管理する新しい項目が増えるたびにStreamで更新するレコードもどんどん増えていくことになってコストがあがっていく
- SQLでいうところのdistinctがないのでアプリ側で重複を省いてる
- この設計だと複数の検索条件にヒットするとid取得の段階でidの重複が発生することになる
- ライブラリを使ったらもっとすっきり書けたり便利なのかもしれないが今回はそこまで調査していない
- 基本となるデータに変更があった場合にStreamなどで関連レコードを更新する必要がある
- 部分一致のクエリの書き方を検索していると今は非推奨の古い書き方例がかなりよく出てくるので注意が必要
- SDKのresourceは古いため非推奨となっており、代わりにclientを使うことが推奨されている*4
参考
- 特に参考にした記事
- DynamoDBのテーブル設計における多対多の考え方
- クエリのパフォーマンスと継続した負荷に対してDynamoDBはどのように対応するかについての検証記事 https://aws.amazon.com/jp/blogs/news/part-2-scaling-dynamodb-how-partitions-hot-keys-and-split-for-heat-impact-performance/
- 今回は触れなかったけどlimitを使うときのハマりそうな注意点 https://www.denzow.me/entry/2018/02/04/130419