1. はじめに
こんにちは、RevComm Researchでリサーチエンジニアとして働いている髙瀬です。 2023年1月上旬にUltralytics社からYOLOv8が公開されました。 今回はYOLOv8について、v5との変更点や動かし方を紹介していこうと思います。
2. YOLOとは
非常に有名な物体検出手法なので、ご存知の方も多いと思います。 YOLOは、CVPR2016でJoseph Redmon氏らが発表したYou Only Look Once: Unified, Real-Time Object Detectionという論文で提案された物体検出手法です。 YOLOという名称はYou Only Look Once(見るのは一度だけ)の略称です。
YOLOは当時の物体検出手法で課題となっていた処理速度の遅さを、物体の検出と識別を同時に行うことで改善しました。 このため、推論速度が非常に高速でリアルタイム物体検出の先駆けにもなっています。
今日に至るまでに様々な物体検出手法が登場していますが、その中でも物体検出に興味を持ち始めた方、これから学ぼうとしている方には是非一度はチェックしてもらいたい手法の一つです。 本記事では詳細な説明は割愛しますが、日本語のわかりやすい解説記事も豊富ですので調べてみてはいかがでしょうか。
3. YOLOv8
YOLOv8は、YOLOv5の公開元であるUltralytics社が公開したYOLOの最新バージョンのモデルです。 大規模データセットでの学習はもちろんのこと、object detection, segmentation, classificationタスクで利用可能であり、CPU, GPUを始めとしたさまざまなハードウェアでの実行が可能になっています。
YOLOv8では、新しいbackboneや損失関数、anchor-free detection headの導入などの変更が加えられているだけでなく、過去のバージョンのYOLOをサポートし異なるバージョン間の切り替えや性能比較を容易にするといった機能を備えている点も大きな特徴と言えます。 現在、リポジトリを確認するとv3, v5, v8のconfigが用意されています。
なお、本記事執筆時点ではYOLOv8の論文は未公開のため、公式からの続報を待ちたいと思います。
4. YOLOv8のモデルサイズ
YOLOv8にはモデルサイズが異なるn, s, m, l, xの5パターンのprerained modelが用意されています。
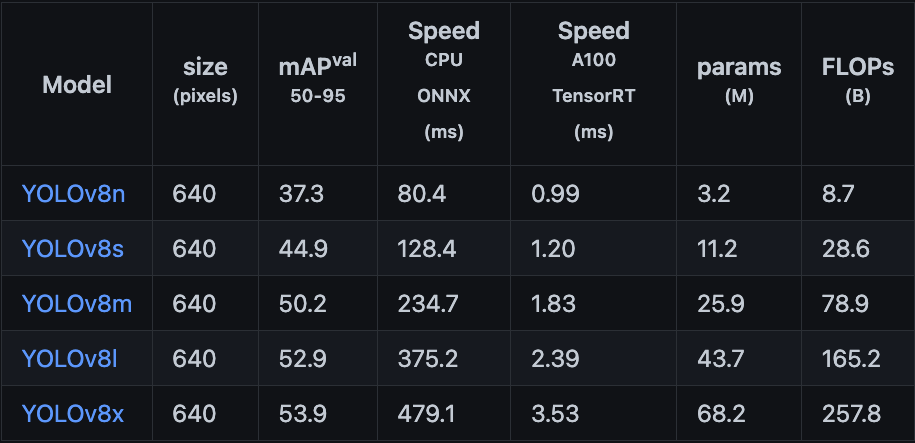
下記のパラメータ数とCOCO mAP(精度)に着目するとYOLOv5から精度がかなり向上していることがわかります。
特に大きいモデルサイズであるl, xはパラメータ数を削減しつつ精度が向上しています。[引用]

{kind=link}
各モデルの精度は下記のようになっています。[引用]
5. YOLOv5とYOLOv8の変更点
YOLOv8になったことでYOLOv5から構成がいくつか変更されていますが、現時点で公開されているモデルの構成から読み取れる大きな変更は2点です。
- C2f layerの導入
- Decoupled head導入とobjectness branchの削除
この他にも一部のconv module削除、kernel sizeの変更など細かな変更が加えられています。
公式ではありませんが、RangeKing氏が公開しているYOLOv8 detection modelアーキテクチャの図が参考になります。

6. YOLOv8の環境構築と推論実行
本章では、YOLOv8をインストールして実際に触れていこうと思います。 今回はpretrained modelを使ってM1 MacBook ProのCPU環境でどの程度動くのか気になったので検証してみます。
<筆者の環境>
- MacBook Pro (13-inch, M1, 2020)
- 16GB
- Mac OS Monterey
YOLOv8のインストールは、下記のコマンドでできます。
pip install ultralytics
インストールが完了したところで、実際に動かしてみます。 今回はPythonスクリプトで推論してみます。
画像に対しての推論
まずは画像を入力してみます。 本記事では公式からダウンロードできる、バスと人が映った画像を使います。 画像サイズはwidth=810, height=1080のRGB画像です。
{kind=link}
from ultralytics import YOLO # load pretrained model. model: YOLO = YOLO(model="yolov8n.pt") # inference # save flgをTrueにすることで推論結果を描画した画像を保存できる。 result: list = model.predict("https://ultralytics.com/images/bus.jpg", save=True)

動画に対しての推論
動画に対しても推論を行ってみました。 画像に対しての推論ではYOLOv8nを使っていたので、動画ではYOLOv8xを使ってみようと思います。
画像の推論時とインターフェースは変わらず、動画ファイルのパスを引数に渡します。
from ultralytics import YOLO # load pretrained model. model: YOLO = YOLO(model="yolov8x.pt") # <figure class="figure-image figure-image-fotolife" title="YOLOv8xの推論結果のgif">[f:id:yasaka_uta:20230327173819g:plain]<figcaption>YOLOv8xの推論結果のgif</figcaption></figure>inference # save flgをTrueにすることで推論結果を描画した動画が保存される。 result: list = model.predict("MOT17-14-FRCNN-raw.mp4", save=True)
今回、MOT Challenge MOT17のTest setの動画を利用します。 なお、MOT17の動画ファイルはWebM形式なので、事前にMP4形式に変換を行っています。 変換した動画は30秒、フレームレートは30なので、900枚の画像に対して推論が行われる形になります。
補足
1. サポートされている動画像のファイル形式
YOLOv8でサポートしている画像、動画のファイル形式は以下のようになっています。
- 画像: "bmp", "dng", "jpeg", "jpg", "mpo", "png", "tif", "tiff", "webp", "pfm"
- 動画: "asf", "avi", "gif", "m4v", "mkv", "mov", "mp4", "mpeg", "mpg", "ts", "wmv"
2. 検出結果のテキスト出力
推論を行っている時に検出結果をテキストとして保存したいことがあると思いますが、下記のように引数を設定すれば可能になります。
# 検出結果を描画した画像と検出結果をテキストに出力したいとき model.predict("https://ultralytics.com/images/bus.jpg", save=True, save_txt=True) # 検出結果+各物体のconfidenceをテキストに出力したいとき model.predict("https://ultralytics.com/images/bus.jpg", save_txt=True, save_conf=True)
Prediction関数に設定できる引数はほかにも用意されているので、公式ドキュメントを参照ください。
3. modelへの入力方法の補足
動作確認で動画像のパスを指定していますが、以下のようにlist形式で複数の動画像のパスを渡すこともできます。
source_list: list = ["./sample1.jpg", "./sample2.jpg"] result: list = model.predict(source_list, save=True)
7. 各モデルの推論結果を俯瞰してみる
前章で環境構築し推論できることが確認できたので、この環境を使ってYOLOv8のsからlのモデルで推論してみようと思います。 また、結果の比較としてYOLOv5だけでなく、ここ1年以内に出ているYOLOv6およびYOLOv7の出力結果も一緒に比較してみます。
なお、今回は各モデルの精度比較ではなく、モデルごとの出力を俯瞰するかたちで比較したいと思います。
YOLOv5, YOLOv6, YOLOv7についての解説は割愛しますが、気になった方は調べてみてください。※YOLOv6のモデルはYOLOv6 (v3.0) がYOLOv8とほぼ同時に公開されているため、YOLOv6 (v3.0)を使っています
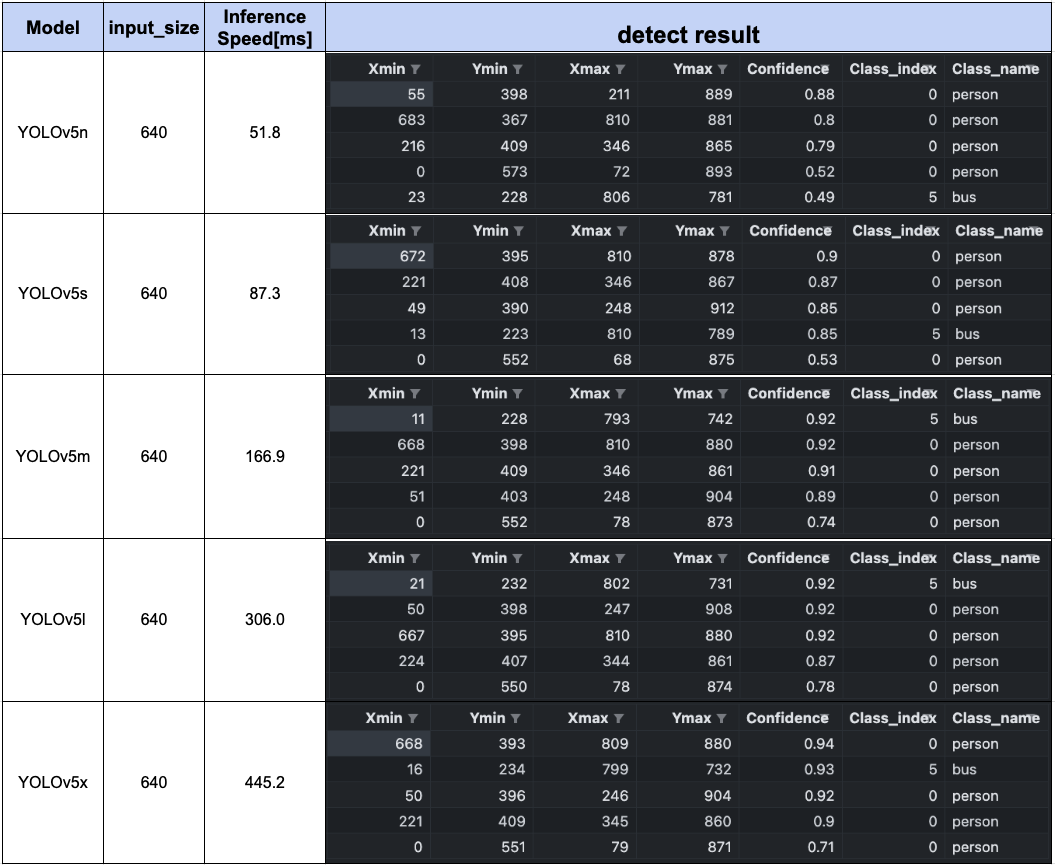
対象とする画像はYOLOv8のサンプル画像を利用しています。 各モデルの検出結果を描画した画像と検出物体の情報、推論速度をまとめてみました。
YOLOv8l, xではYOLOv5l, xで検出できていなかった画像右上のbicycleを検出できていますね。 YOLOv8の検出物体のconfidenceをみていくとYOLOv5よりも基本的に向上していることがわかります。 YOLOv7が若干遅い印象はあるものの、どのモデルもかなり高速ですね。
YOLOv8


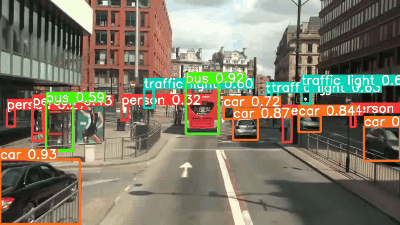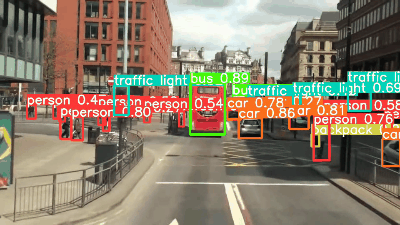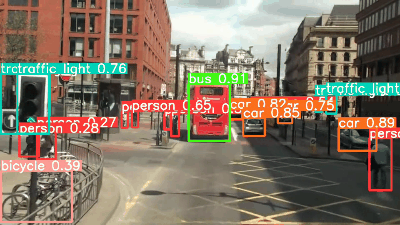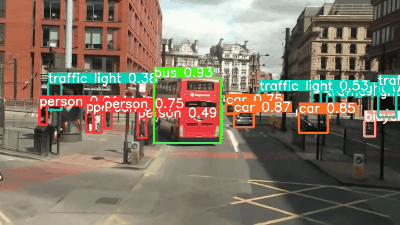
YOLOv5

YOLOv6(v3.0)


YOLOv7


8. まとめ
本記事では、YOLOv8の概要・YOLOv5との差分・簡単な使い方を紹介しました。 YOLOv8を使ってみた所感としては、
- pip install可能で導入が容易、かつ使いやすく整理されたインターフェース
- onnx, torchscriptなどへの変換が非常に簡単
以前のYOLOv5も使いやすかったですが、さらに利便性が向上した印象を持ちました。 モデルのexportについては今回触れていませんが、export形式が豊富で簡単に実行できるのは開発者にとってうれしいですね。
9. 参考文献
- https://github.com/ultralytics/ultralytics
- https://docs.ultralytics.com/
- https://github.com/meituan/YOLOv6
- https://github.com/WongKinYiu/yolov7
- https://github.com/ultralytics/yolov5
- https://github.com/ultralytics/ultralytics/issues/189
- https://motchallenge.net/data/MOT17/
- https://blog.roboflow.com/whats-new-in-yolov8/